I have a 2 dimensional pandas dataframe that has as the index the values "1, 2, 'NaN', 'NaN', 'NaN', 'NaN'" and the data [10, 20, 30, 40, 50 , 60]. Now I would like to build a numpy array with the dimensionality (3,2). In the first entry of the first dimension of the array, the first two values of the dataframe should be assigned. In the second entry of the first dimension the 3rd and 4th value of the dataframe should be assigned and so on.
So actually the new array should look like this
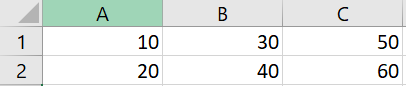
I tried it with the following code but it did not work, as I get a "KeyError: 0"
import pandas as pd
import numpy as np
d = {'col1': [1, 2, 'NaN', 'NaN', 'NaN', 'NaN'], 'col2': [10, 20, 30, 40, 50 , 60]}
df1 = pd.DataFrame(data=d)
df1 = df1.set_index('col1')
firstDimensionOfTheArray = 3
secondDimensionOfTheArray = 2
array = np.zeros((firstDimensionOfTheArray, secondDimensionOfTheArray))
for i in range (0, firstDimensionOfTheArray):
for j in range (0, secondDimensionOfTheArray):
array [i, j] = df1 ['col2'] [i * secondDimensionOfTheArray j]
Do you have any idea, how to do that?
CodePudding user response:
To build the numpy array, use to_numpy and reshape:
df1['col2'].to_numpy().reshape((2,3), order='F')
output:
array([[10, 30, 50],
[20, 40, 60]])
Now, to make a new dataframe, wrap the above in a DataFrame constructor:
import string
pd.DataFrame(df1['col2'].to_numpy().reshape((2,3), order='F'),
# the two lines below are only needed if you want
# the same indexes as in your image
index=list(df1.index[:2]),
columns=list(string.ascii_uppercase[:3])
)
output:
A B C
1 10 30 50
2 20 40 60
CodePudding user response:
Using the SO answer, can solve the problem of your written code by adding iloc:
array[i, j] = df1['col2'].iloc[i * secondDimensionOfTheArray j]
or use iat instead of iloc. The solution will get the result for your example:
[[10. 20.]
[30. 40.]
[50. 60.]]
Then you can get the desired result by just transposing the array:
array = array.T
output:
[[10. 30. 50.]
[20. 40. 60.]]