I am reading an excel file for which I want to drop some initial rows and columns WHILE reading it. There is a very good option to drop initial rows using skip_rows option. But I am unable to find any option which will help me drop initial columns.
df1=pd.read_excel(r"file_name.xlsx",
skiprows=4)
As in my code above, I am able to skip initial 4 rows. Is there any similar option by which I can skip initial 4 columns while reading this excel?
I think its a very basic question and I also tried finding its solution. But unable to do it. Every solution using either names of the columns or total number of columns as parameter.
CodePudding user response:
If your excel file looks like:
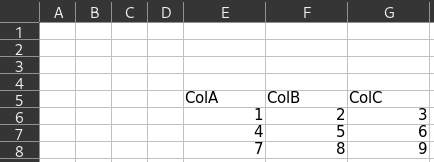
You can use usecols as below:
>>> pd.read_excel('data.xlsx', skiprows=4,
usecols=lambda x: x if not x.startswith('Unnamed') else None)
ColA ColB ColC
0 1 2 3
1 4 5 6
2 7 8 9
Update
Another (ugly?) method: create a counter outside of the function. Each time the function keepcol is called, decrement the counter until it reaches 0. After that, all columns are kept.
skip_cols = 4
def keepcol(name):
global skip_cols
if skip_cols == 0:
return name
skip_cols -= 1
pd.read_excel('data.xlsx', skiprows=4, usecols=keepcol)
CodePudding user response:
You can use range with usecols during reading as:
df1 = pd.read_excel(r"file_name.xlsx", skiprows=4,
usecols=range(4, len(pd.read_excel(r"file_name.xlsx").columns)))
CodePudding user response:
You can use the following ways to solve your question
- Making use of “columns” parameter of drop method
- Select columns by indices and drop them : Pandas drop unnamed columns
- Pandas slicing columns by index : Pandas drop columns by Index
- Python’s “del” keyword :
- Selecting columns with regex patterns to drop them
- Dropna : Dropping columns with missing values
For more information refer the documentation