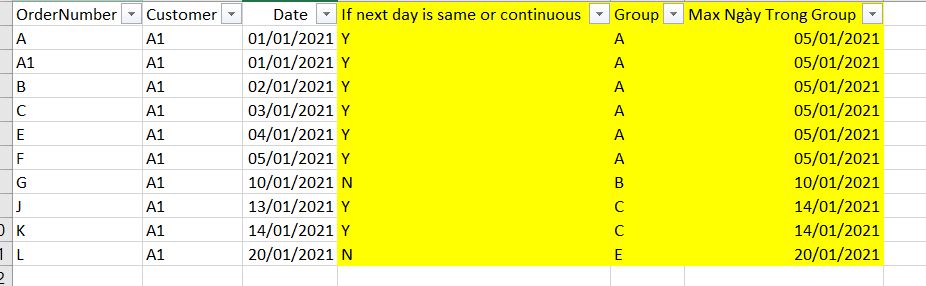
I have a data like I show in the attached picture. What I want is if the next value is same or equal to the current value 1, then I will put them in the same group. The group need to be different between customers.
for example:
(dd-mm-yyyy)
Customer A1 1/1/2020 - Group A
Customer A1 1/1/2020 - Group A
Customer A1 2/1/2020 - Group A
Customer A1 3/1/2020 - Group A
Customer A1 3/1/2020 - Group A
Customer A1 5/1/2020 - Group B
Customer A1 10/1/2020 - Group C
Customer A1 13/1/2020 - Group D
Customer A1 14/1/2020 - Group D
Customer A1 20/1/2020 - Group E
Customer B1 21/1/2020 - Group A
Customer B1 22/1/2020 - Group A
Customer B1 24/1/2020 - Group B
Customer B1 27/1/2020 - Group C
Customer B1 28/1/2020 - Group C
How can I resolve it in pandas?
CodePudding user response:
First ensure that your date column is of datetime type, then perform a diff to get a timedelta and apply a cumsum on the deltas that are above 1 day. To get letters, you can map the obtained number to chr, but keep in mind that you'll have a limited number of groups (or you need to write a slightly more complex mapping to generate AA after Z: example here)
I provided both a numerical and letter grouping.
df['date'] = pd.to_datetime(df['date'], dayfirst=True)
df['group'] = df['date'].diff().gt(pd.to_timedelta('1d')).cumsum()
df['group2'] = 'Group ' df['group'].map(lambda x: chr(65 x))
Output:
date group group2
0 2020-01-01 0 Group A
1 2020-01-02 0 Group A
2 2020-01-03 0 Group A
3 2020-01-03 0 Group A
4 2020-01-05 1 Group B
5 2020-01-10 2 Group C
6 2020-01-13 3 Group D
7 2020-01-14 3 Group D
8 2020-01-20 4 Group E
same process per group
df['date'] = pd.to_datetime(df['date'], dayfirst=True)
df['group'] = (df.groupby('customer')['date'].diff()
.gt(pd.to_timedelta('1d'))
.groupby(df['customer']).cumsum()
)
df['group2'] = 'Group ' df['group'].map(lambda x: chr(65 x))
output:
customer date group group2
0 Customer A1 2020-01-01 0 Group A
1 Customer A1 2020-01-01 0 Group A
2 Customer A1 2020-01-02 0 Group A
3 Customer A1 2020-01-03 0 Group A
4 Customer A1 2020-01-03 0 Group A
5 Customer A1 2020-01-05 1 Group B
6 Customer A1 2020-01-10 2 Group C
7 Customer A1 2020-01-13 3 Group D
8 Customer A1 2020-01-14 3 Group D
9 Customer A1 2020-01-20 4 Group E
10 Customer B1 2020-01-21 0 Group A
11 Customer B1 2020-01-22 0 Group A
12 Customer B1 2020-01-24 1 Group B
13 Customer B1 2020-01-27 2 Group C
14 Customer B1 2020-01-28 2 Group C
CodePudding user response:
Here is one of the approach:
import pandas as pd
from datetime import datetime
date_format = "%d/%m/%Y"
df = pd.DataFrame({
'Date': ['01/01/2021', '01/01/2021', '02/01/2021', '04/01/2021', '05/01/2021'],
})
df['Group'] = ''
start_date = df['Date'][0]
group = ord('A')
for i in range(len(df)):
date = df['Date'].values[i]
current_date = datetime.strptime(date , date_format)
previous_date = datetime.strptime(start_date, date_format)
if (current_date - previous_date).days > 1:
group = 1
df['Group'].values[i] = chr(group)
start_date = date
print (df)
Output:
Date Group
0 01/01/2021 A
1 01/01/2021 A
2 02/01/2021 A
3 04/01/2021 B
4 05/01/2021 B