I'm trying to download this test json file to use it in a classification project.I have the converted this JSON file to a csv file in pandas using this code:
test_sarcasm_df = pd.read_json('/content/drive/My Drive/Sarcasm Data/test_sarcasm.json')
I am using it in an ML project but it's in the wrong format. I'm not familiar with JSON and its a big file so is there any way I can format it where the first column becomes the first row in my dataframe?
I appreciate any help you guys can give me!
Here is what the data frame looks like:
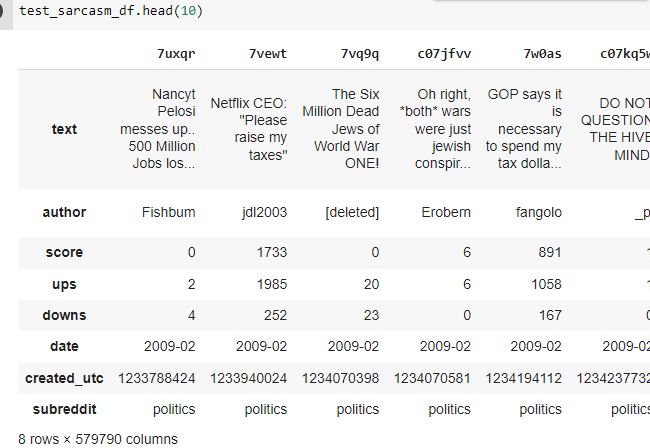
CodePudding user response:
Pandas transpose solves this problem exactly:
from pandas import DataFrame
df = DataFrame([{"row1": "text2", "row2": "text1"},{"row1": "bob", "row2": "james"}])
df.index = ["text", "author"]
print(df.head(2))
# this is essentially the starting position
row1 row2
text text2 text1
author bob james
# now we transpose
df = df.transpose()
print(df.head(2))
# problem solved :)
text author
row1 text2 bob
row2 text1 james