I have to make a task where we need to check if a symbol is a valid symbol (by the rules of the task)
The background information of the task which I probably won't be able to explain:
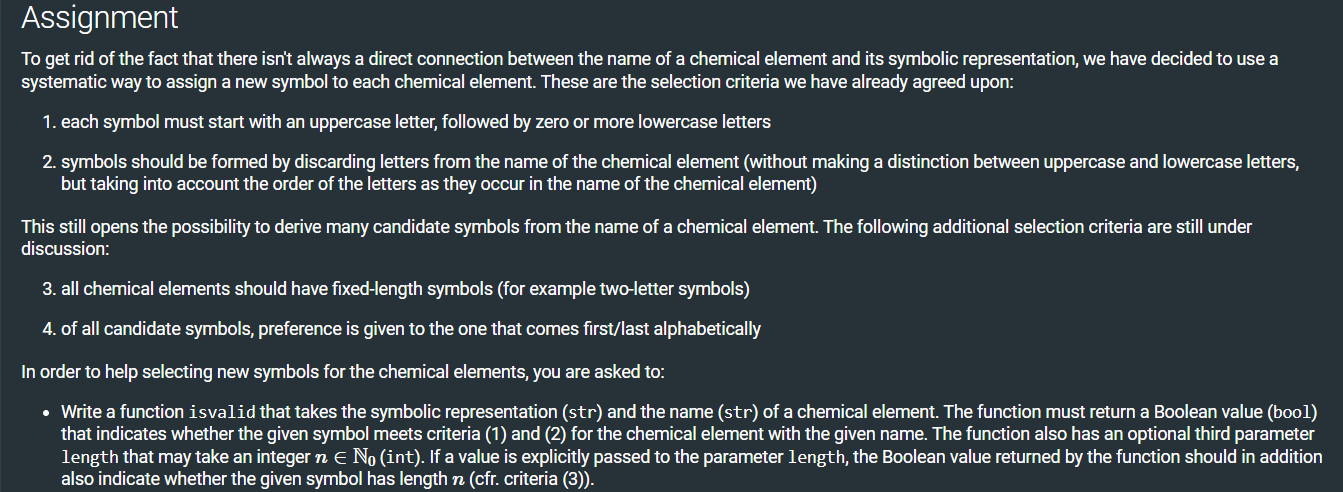
Example provided by the assignment:
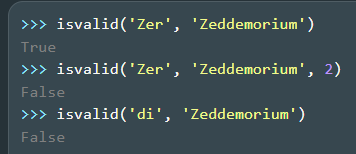
def isvalid(symbol, element, length = None):
elbool = False
if symbol[0]!=symbol[0].upper():
return False #first letter in the symbol has to be a capital letter
for i in range(len(symbol)-1):
if element.find(symbol[i 1])>element.find(symbol[i]): #checking if the order is correct
elbool = True
else:
return False
if length is not None:
if len(symbol)!=length:
return False
else:
elbool = True
return elbool
Is my code now but it doesn't work for example with this one: isvalid('Rcm', 'Americium') because there is an m before the c and it counts that one.
So I think I need to split the element string from the last letter in the symbol so I don't have that problem but how do I do that?
Sorry if the question is a bit confusing.
CodePudding user response:
You need to use .find(needle, start_pos) to look for the character after a certain location in element. Also, you don't need to mess with indices and keep finding the previous and current character from symbol. Just keep track of the location of the current character for the next iteration.
You should also do a case-insensitive search, because, using your example, there is no "R" in "Americium". I do this by converting element to lowercase once, and then doing .find(c.lower(), ...) on each character in symbol
Finally, you forgot to check that all characters other than the first one in symbol are lowercase. I also added that to the for loop.
element = element.lower() # Lowercase element so that we can find characters correctly
lastfound = 0
for ix, c in enumerate(symbol):
if ix > 0 and c.isupper():
# Not the first character, and is uppercase
return False
thisfound = element.find(c.lower(), lastfound) # Find the location of this character
if thisfound == -1: # character not found in element after location lastfound
return False
lastfound = thisfound # Set lastfound for the next iteration
A few other minor suggestions:
- You can
return Falseas soon as you find something wrong. Then, at the end of the function, justreturn Truebecause the only way you reach the end is when nothing is wrong. - You can check if a character is lowercase with
symbol[0].islower(). No need to dosymbol[0] != symbol[0].upper(). - You should check for the length requirement before you check for the order of characters, because that's the simpler check.
Applying all these:
def isvalid(symbol, element, length = None):
if symbol[0].islower():
return False
if length is not None and len(symbol) != length:
return False
element = element.lower() # Lowercase element so that we can find characters correctly
lastfound = 0
for ix, c in enumerate(symbol):
if ix > 0 and c.isupper():
return False
thisfound = element.find(c.lower(), lastfound) # Find the location of this character
if thisfound == -1: # character not found in element after location lastfound
return False
lastfound = thisfound # Set lastfound for the next iteration
return True
Using your tests:
>> isvalid('Zer', 'Zeddemorium')
True
>> isvalid('Zer', 'Zeddemorium', 2)
False
>> isvalid('di', 'Zeddemorium')
False
>> isvalid('Rcm', 'Americium')
True