I want to restructure my land use classification dataframe and add new rows and columns based on conditions of the dataframe. I've been using dplyr to try this, however the examples I have found tend to decrease the columns or rows and not increase the number of rows based off conditions. I have tried to loop through the dataset to add the rows, but want to know if there is a better way to do it in dplry? I'm open to using a different library as well but its a very large dataset of classifications and dplyr seems to work well with the dataframe?
Here is the code example of what my current dataframe looks like (df_old) and what I would like it to be in the end (df_new).
What I want to do, is everytime the Year1990-2015 changes it creates a new row. Example: ID 424, in 1990 it is 51, but in the Year 2000 it changes to 21 and remains 21 until present day. This means that the new dataframe for ID 424 should ahve two rows. One labeled Start_Year that represents the begining of the land use in 1990 as Forest (Landuse = 51) and remains Forest until it changes in 2000. Since in 2000 it is Pavement, we assume it was Forest still in 1999 and End_Year will be 1999 for the first row of ID 424. Than a new row appears for ID 424 where Start_Year is 2000 as it changed to Pavement (Landuse = 21) and remains 21 until End_year (Present day).
To add context, the dataset represents how an area changes in a city, where the numbers in Year1990-2015 are used to identify different landuse classifications( 21 = Pavement, 24 = Park, 25 = Residential, 51 = Forest, 41 = Agriculture).
df_old <- data.frame(ID = c(424,426,427,428),
Parameter= c(0.01,0.03,0.03,0.01),
City = c("Abbotsford","Abbotsford","Abbotsford","Abbotsford"),
Area = c(3.12,7.98,2.01,0.48),
Year1990 = c(51,51,51,41),
Year2000 = c(21,51,51,41),
Year2005 = c(21,51,51,25),
Year2010 = c(21,51,51,24),
Year2015 = c(21,51,51,25))
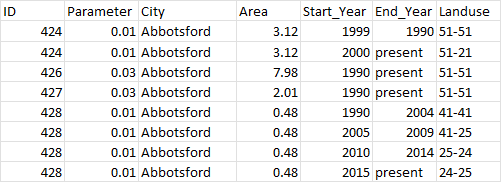
df_new <- data.frame(ID = c(424,424,426,427,428,428,428,428),
Parameter= c(0.01,0.01,0.03,0.03,0.01,0.01,0.01,0.01),
City = c("Abbotsford","Abbotsford","Abbotsford","Abbotsford","Abbotsford","Abbotsford","Abbotsford","Abbotsford"),
Area = c(3.12,3.12,7.98,2.01,0.48,0.48,0.48,0.48),
Start_Year = c(1990,2000,1990,1990,1990,2005,2010,2015),
End_Year = c(1999,"present","present","present",2004,2009,2014,"present"),
Landuse = c("51-51","51-21","51-51","51-51","41-41","41-25","25-24","24-25"))

This is what I would like the final product to be:
CodePudding user response:
This solution works for your example data, but it's difficult to determine the 'rules' governing your required manipulations (and therefore difficult to know whether it will work with your real data). If this fails on your real data, please edit your post with more info.
library(tidyverse)
df_old <- data.frame(ID = c(424,426,427,428),
Parameter= c(0.01,0.03,0.03,0.01),
City = c("Abbotsford","Abbotsford","Abbotsford","Abbotsford"),
Area = c(3.12,7.98,2.01,0.48),
Year1990 = c(51,51,51,41),
Year2000 = c(21,51,51,41),
Year2005 = c(21,51,51,25),
Year2010 = c(21,51,51,24),
Year2015 = c(21,51,51,25))
df_new <- data.frame(ID = c(424,424,426,427,428,428,428,428),
Parameter= c(0.01,0.01,0.03,0.03,0.01,0.01,0.01,0.01),
City = c("Abbotsford","Abbotsford","Abbotsford","Abbotsford","Abbotsford","Abbotsford","Abbotsford","Abbotsford"),
Area = c(3.12,3.12,7.98,2.01,0.48,0.48,0.48,0.48),
Start = c(1990,2000,1990,1990,1990,2005,2010,2015),
End = c(1999,"present","present","present",2004,2009,2014,"present"),
LU = c("51-51","51-21","51-51","51-51","41-41","41-25","25-24","24-25"))
df_old %>%
pivot_longer(cols = -c(1:4)) %>%
group_by(ID) %>%
mutate(Start = as.numeric(str_extract(name, "\\d "))) %>%
mutate(`LU-LU` = paste(lag(value, default = max(value)), "-", value, sep = "")) %>%
distinct(`LU-LU`, .keep_all = TRUE) %>%
group_by(ID) %>%
filter(value != lag(value, default = 0)) %>%
group_by(ID) %>%
mutate(End = lead(Start, default = NA) - 1,
End = replace_na(End, "present")) %>%
select(c(ID, Parameter, City, Area, Start, End, `LU-LU`))
#> # A tibble: 8 × 7
#> # Groups: ID [4]
#> ID Parameter City Area Start End `LU-LU`
#> <dbl> <dbl> <chr> <dbl> <dbl> <chr> <chr>
#> 1 424 0.01 Abbotsford 3.12 1990 1999 51-51
#> 2 424 0.01 Abbotsford 3.12 2000 present 51-21
#> 3 426 0.03 Abbotsford 7.98 1990 present 51-51
#> 4 427 0.03 Abbotsford 2.01 1990 present 51-51
#> 5 428 0.01 Abbotsford 0.48 1990 2004 41-41
#> 6 428 0.01 Abbotsford 0.48 2005 2009 41-25
#> 7 428 0.01 Abbotsford 0.48 2010 2014 25-24
#> 8 428 0.01 Abbotsford 0.48 2015 present 24-25
Created on 2021-12-03 by the reprex package (v2.0.1)