I am looking to join two data frames using the pd.merge_asof function. This function allows me to match data on a unique id and/or a nearest key. In this example, I am matching on the id as well as the nearest date that is less than or equal to the date in df1.
Is there a way to prevent the data from df2 being recycled when joining?
This is the code that I currently have that recycles the values in df2.
import pandas as pd
import datetime as dt
df1 = pd.DataFrame({'date': [dt.datetime(2020, 1, 2), dt.datetime(2020, 2, 2), dt.datetime(2020, 3, 2)],
'id': ['a', 'a', 'a']})
df2 = pd.DataFrame({'date': [dt.datetime(2020, 1, 1)],
'id': ['a'],
'value': ['1']})
pd.merge_asof(df1,
df2,
on='date',
by='id',
direction='backward',
allow_exact_matches=True)
This is the output that I would like to see instead where only the first match is successful
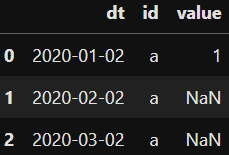
CodePudding user response:
Given your merge direction is backward, you can do a mask on duplicated id and df2's date after merge_asof:
out = pd.merge_asof(df1,
df2.rename(columns={'date':'date1'}), # rename df2's date
left_on='date',
right_on='date1', # so we can work on it later
by='id',
direction='backward',
allow_exact_matches=True)
# mask the value
out['value'] = out['value'].mask(out.duplicated(['id','date1']))
# equivalently
# out.loc[out.duplicated(['id', 'date1']), 'value'] = np.nan
Output:
date id date1 value
0 2020-01-02 a 2020-01-01 1
1 2020-02-02 a 2020-01-01 NaN
2 2020-03-02 a 2020-01-01 NaN