I want to run multiple queries in Snowflake and extract the results in one go... i.e. run all the SQL for the top ten rows in each table. Do I have to run and download each one separately, or can it be done in one go?
CodePudding user response:
You can use a union to stack tables in the the same result set. Unions require that you have the same # of columns, so we can just insert null columns in the select.
You'll have to add as many 'fake' columns needed to each subsequent table 'till it = the amount of columns in the table with most columns.
Select TOP 10 Col1, Col2, Col3, Col4, Col5
FROM Table1
Union
Select TOP 10 Col1, Col2, Col3, Null as Col4, Null as Col5
FROM Table2
Select TOP 10 Col1, Col2, Null as col3, Null as Col4, Null as Col5
FROM Table3
You can also replace the real columns with an *, and only list the fake columns
Select TOP 10 Col1, Col2, Col3, Null as Col4, Null as Col5
FROM Table2
Select TOP 10 *, Null as col3, Null as Col4, Null as Col5
FROM Table3
Not sure if this will work in your specific SQL DB dialect.
CodePudding user response:
The SQL UNION Operator The UNION operator is used to combine the result-set of two or more SELECT statements.
Every SELECT statement within UNION must have the same number of columns The columns must also have similar data types The columns in every SELECT statement must also be in the same order UNION Syntax
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;
Stack multiple tables using UNION ALL A. Syntax to combine the tables in SQL Server The syntax is quite simple, we combine the select queries of the individual tables with a UNION or UNION ALL:
SELECT [EmpID]
,[Name]
,[LocationID]
,[Location]
,[Year]
,[Target]
FROM [TargetShire]
UNION
SELECT [EmpID]
,[Name]
,[LocationID]
,[Location]
,[Year]
,[Target]
FROM [TargetCentralMiddleEarth]
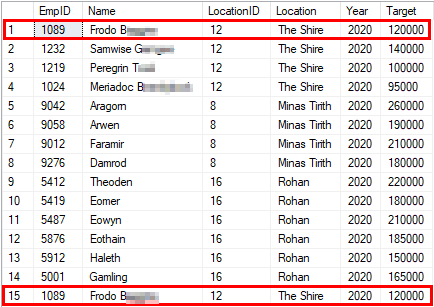
As a result we receive the combined tables:
Handling of duplicate entries in SQL Server
If you paid attention, the duplicate entry of the employee "Frodo B." is missing in the example above. This is because the "UNION" command removes duplicate values.
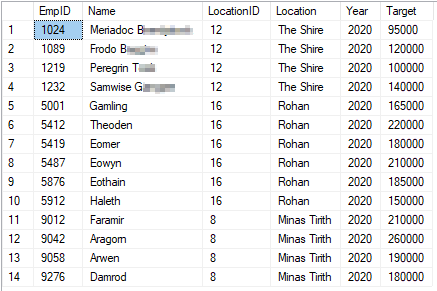
If we want to have the duplicate entries as well, we have to use "UNION ALL". The syntax is similar to the example above:
SELECT [EmpID]
,[Name]
,[LocationID]
,[Location]
,[Year]
,[Target]
FROM [TargetShire]
UNION ALL
SELECT [EmpID]
,[Name]
,[LocationID]
,[Location]
,[Year]
,[Target]
FROM [TargetCentralMiddleEarth]