I have two dataframes df1 and df2 which I have merged together into another dataframe df3
df1 <- data.frame(
Name = c("A", "B", "C"),
Value = c(1, 2, 3),
Method = c("Indirect"))
df2 <- data.frame(
Name = c("A", "B"),
Value = c(4, 5),
Method = c("Direct"))
df3 <- rbind(df1, df2)
So df3 looks something like this
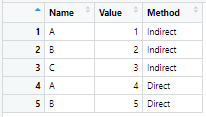
Now I need to identify all the unique entries in the Name column (which is C in this case) and for each of the unique entries, a row is to be added which would have the same "Name" but "Value" would be 0 and the "Method" would be the opposite one. The output should look like this.
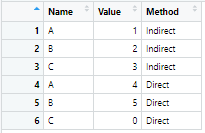
Finally the rows with similar "Name" are to be arranged one below the other.
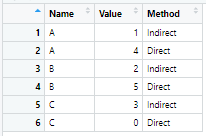
I have a huge dataframe and I need to achieve the above mentioned outcome in the most efficient way in R. How do I proceed?
CodePudding user response:
One way
tmp=df3[!(df3$Name %in% df3$Name[duplicated(df3$Name)]),]
tmp$Value=0
tmp$Method=ifelse(tmp$Method=="Direct","Indirect","Direct")
Name Value Method
3 C 0 Direct
you can now rbind this to your original data (and sort it).
CodePudding user response:
Please find another solution using data.table
Reprex
- Code
library(data.table)
library(magrittr) # for the pipe!
setDT(df3)
df3 <- rbindlist(list(df3,
df3[!(df3$Name %in% df3[duplicated(Name)]$Name)
][, `:=` (Value = 0, Method = fifelse(Method == "Indirect", "Direct", "Indirect"))])) %>%
setorder(., Name)
- Output
df3
#> Name Value Method
#> 1: A 1 Indirect
#> 2: A 4 Direct
#> 3: B 2 Indirect
#> 4: B 5 Direct
#> 5: C 3 Indirect
#> 6: C 0 Direct
Created on 2021-12-15 by the reprex package (v2.0.1)
CodePudding user response:
I think that with 10,000 rows you will barely notice it:
library(dplyr)
df3 |>
add_count(Name) |>
filter(n == 1) |>
mutate(
Value = 0,
Method = c(Indirect = 'Direct', Direct = 'Indirect')[Method],
n = NULL
) |>
bind_rows(df3) |>
arrange(Name, Value, Method)
# Name Value Method
# 1 A 1 Indirect
# 2 A 4 Direct
# 3 B 2 Indirect
# 4 B 5 Direct
# 5 C 0 Direct
# 6 C 3 Indirect