I have a time-series panel dataset which is structured in the following way: There are multiple funds that each own multiple stocks and we have the time series of the weight of the stock within that portfolio and the total value of the portfolio for that year. As you can see the panel is not balanced.
df <- data.frame(
fund_id = c(1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 3L, 3L, 3L, 3L, 3L),
stock_id = c(1L, 1L, 2L, 2L, 2L, 1L, 1L, 1L, 2L, 2L, 3L, 3L, 2L, 2L, 3L, 3L, 3L),
year = c(2011L, 2012L, 2011L, 2012L, 2013L, 2011L, 2012L, 2013L, 2012L,2013L, 2011L, 2012L, 2013L, 2014L, 2011L, 2012L, 2013L),
weight = c(0.3L, 0.2L, 0.7L, 0.8L, 1L, 0.2L, 0.1L, 0.2L, 0.7L, 0.8L, 0.8L, 0.2L, 0.3L, 1L, 0.5L, 0.2L, 0.7L),
aum = c(3L, 3.5L, 3L, 3.5L, 4L, 5L, 4L, 5L, 4L, 5L, 5L, 4L, 6L, 7L, 5L, 6L, 6L)
)
> df
fund_id stock_id year weight aum
1 1 1 2011 0.3 3.0
2 1 1 2012 0.2 3.5
3 1 2 2011 0.7 3.0
4 1 2 2012 0.8 3.5
5 1 2 2013 1.0 4.0
6 2 1 2011 0.2 5.0
7 2 1 2012 0.1 4.0
8 2 1 2013 0.2 5.0
9 2 2 2012 0.7 4.0
10 2 2 2013 0.8 5.0
11 2 3 2011 0.8 5.0
12 2 3 2012 0.2 4.0
13 3 2 2013 0.3 6.0
14 3 2 2014 1.0 7.0
15 3 3 2011 0.5 5.0
16 3 3 2012 0.2 6.0
17 3 3 2013 0.7 6.0
>
I would like to calculate the following formula for each year and each stock:
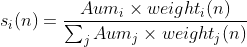
Please note that the i is the fund id and n is the stock id, in this case j should be any other fund except i . The formula is repeated for each year so I dropped the subscript t. aum only depends on the fund_id and year and not on the stock so it would be the same value for the same fund and year but different stock id.
I was thinking about using dplyr to do this but I have a very large panel dataset and not sure how to to about this.
CodePudding user response:
Based on the description, do a group by 'year', 'stock_id', and then multiply the 'aum' with 'weight' while extracting the subset of the whole column 'aum' (.$aum) based on the logical expression (.$fund_id != first(fund_id)) and the 'weight', get the sum and divide with the multiplied 'aum' with 'weight'
library(dplyr)
df %>%
group_by(year, stock_id) %>%
mutate(sn = (aum * weight)/sum(.$aum[.$fund_id != first(fund_id)] *
.$weight[.$fund_id != first(fund_id)])) %>%
ungroup
-output
# A tibble: 17 × 6
fund_id stock_id year weight aum sn
<int> <int> <int> <dbl> <dbl> <dbl>
1 1 1 2011 0.3 3 0.0293
2 1 1 2012 0.2 3.5 0.0228
3 1 2 2011 0.7 3 0.0684
4 1 2 2012 0.8 3.5 0.0912
5 1 2 2013 1 4 0.130
6 2 1 2011 0.2 5 0.0326
7 2 1 2012 0.1 4 0.0130
8 2 1 2013 0.2 5 0.0368
9 2 2 2012 0.7 4 0.0912
10 2 2 2013 0.8 5 0.130
11 2 3 2011 0.8 5 0.147
12 2 3 2012 0.2 4 0.0294
13 3 2 2013 0.3 6 0.0586
14 3 2 2014 1 7 0.286
15 3 3 2011 0.5 5 0.0919
16 3 3 2012 0.2 6 0.0441
17 3 3 2013 0.7 6 0.171