Have got a data similar like below in Google Sheet
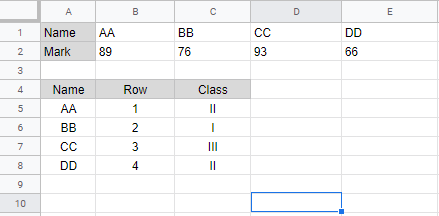
Need to read data range starting from 'A4 to C4' columns as fixed with countless rows(flexible) below in Python. Help me out since I'm new to this Google Sheet with Python.
Expected Output in Python as Dataframe df is below:
Name Row Class
AA 1 II
BB 2 I
CC 3 III
DD 4 II
CodePudding user response:
You can use pandas skiprows like this I've check this and it's working I'm using .ods sheet
import pandas as pd
df = pd.read_excel(
"test.ods", engine="odf",
index_col=None,
header=None,
skiprows=lambda x: x in [0,1,2],
keep_default_na=False
)
print(df)
Output
https://imgur.com/VOQh4s7
for i in df:
print(df[i])
Output
https://imgur.com/8tzsh8F
I know this not a complete solution but little close to it.
CodePudding user response:
In your situation, how about the following sample scripts?
Sample script 1:
If your Spreadsheet is not published as the Web publish, how about the following script? In this sample script, I used googleapis for python. So, about how to use this, please check Python Quickstart for Sheets API. service = build('sheets', 'v4', credentials=creds) in my proposed script is the same with the script of Python Quickstart for Sheets API.
spreadsheet_id = "###" # Please set the Spreadsheet ID.
range_a1Notation = "Sheet1!A4:C" # Please set the range as the A1Notation.
service = build('sheets', 'v4', credentials=creds)
sheet = service.spreadsheets()
result = sheet.values().get(spreadsheetId=spreadsheet_id, range=range_a1Notation).execute()
values = result.get("values", [])
df = pd.DataFrame(values)
Sample script 2:
If your Spreadsheet is published as the Web publish, you can use the following script.
import io
import pandas as pd
import requests
url = 'https://docs.google.com/spreadsheets/d/e/2PACX-###/pub?sheet=Sheet1&range=A4:C&output=csv'
df = pd.read_csv(io.BytesIO(requests.get(url).content), sep=',')
- In this case, please replace
2PACX-###for your Web published URL. Sheet1ofsheet=Sheet1is the sheet name.A4:Cofrange=A4:Cis the rangeA4:Cas the A1Notation.
References:
CodePudding user response:
With openpyxl it is easy and simple:
from openpyxl import load_workbook
wb = load_workbook(filename = 'your_path_to_file.xlsx')
sheet = wb['Your sheet name']
for index, row in enumerate(sheet.iter_rows()):
if index == "your specific index":
"Do something"