I have a csv file with 2 columns. One column has string toxic comments, other column has float toxicity values 0 to 1. (comments become more toxic when toxicity value close to 1).
And I want to do linear regression for correctly predict amount of toxic values.
For that, first I converted the "comment" (string) column to integer like that :
train['comment']= pd.to_numeric(train['comment'], errors='coerce').fillna(0).astype(np.int64)
Then, I wrote that code for linear regression :
linX = train.iloc[:, 0].values.reshape(-1,1)
linY = train.iloc[:, 1].values.reshape(-1,1)
lr = LinearRegression()
lr.fit(linX, linY)
Y_pred = lr.predict(linX)
plt.scatter(linX,linY)
plt.plot(linX,Y_pred, color='red')
That worked but I don't think I did right. Because that regression table didn't seem right to me :
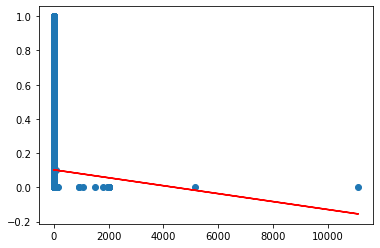
I couldn't solve the problem. My questions is ;
Is my code for linear regression for this problem right ?
Should I split the "toxicity" column seperate from 0 values ?
CodePudding user response:
I'm not sure if turning strings into numeric values with the code below will return the results you are looking for.
pd.to_numeric(train['comment'], errors='coerce')
This code only change the variable type of the string comments. String comments are unable to be converted into integers. The coerce optional parameter causes the strings to be converted into NaN values, and the NaN values are converted into zeros with fillna.
To solve text classification problems using machine learning techniques you will need to preprocess the data using techniques such as TF-IDF.