I have a Delta dataframe containing multiple columns and rows.
I did the following:
Delta.limit(1).select("IdEpisode").show()
---------
|IdEpisode|
---------
| 287 860|
---------
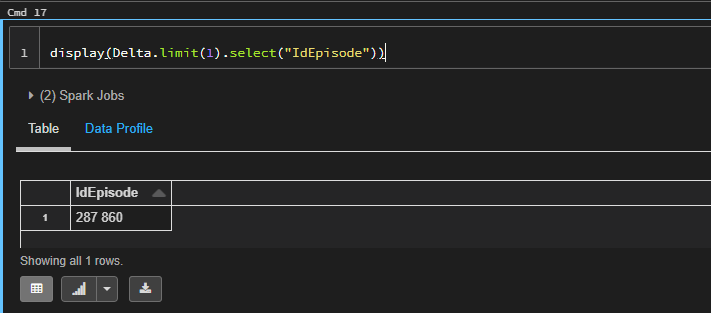
But then, when I do this:
Delta.filter("IdEpisode == '287 860'").show()
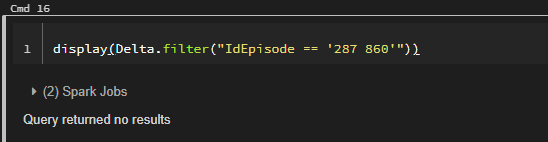
It returns 0 rows which is weird because we can clearly see the Id present in the dataframe.
I figured it was about the ' ' in the middle but I don't see why it would be a problem and how to fix it.
IMPORTANT EDIT:
Doing Delta.limit(1).select("IdEpisode").collect()[0][0]
returned: '287\xa0860'
And then doing:
Delta.filter("IdEpisode == '287\xa0860'").show()
returned the rows I've been looking for. Any explanation ?
CodePudding user response:
This character is called NO-BREAK SPACE. It's not a regular space that's why it is not matched with your filtering.
You can remove it using regexp_replace function before applying filter:
import pyspark.sql.functions as F
Delta = spark.createDataFrame([('287\xa0860',)], ['IdEpisode'])
# replace NBSP character with normal space in column
Delta = Delta.withColumn("IdEpisode", F.regexp_replace("IdEpisode", '[\\u00A0]', ' '))
Delta.filter("IdEpisode = '287 860'").show()
# ---------
#|IdEpisode|
# ---------
#| 287 860|
# ---------
You can also clean your column by using the regex \p{Z} to replace all kind of spaces with regular space:
\p{Z}or\p{Separator}: any kind of whitespace or invisible separator.
Delta = Delta.withColumn("IdEpisode", F.regexp_replace("IdEpisode", '\\p{Z}', ' '))