I have a df which I am writing to an excel.
But first I create a new dataframe which has a column and its value is an excel formula.
next_sheet = pd.DataFrame()
next_sheet['SUM'] = '=SUM(first!D2:first!D4)'
As you can see, sheets second & third share the same formula inside of them.
df_res.to_excel('testing.xlsx', sheet_name='first') # main sheet with data
with pd.ExcelWriter('testing.xlsx', engine="openpyxl", mode="a") as writer:
pd.DataFrame(data = ['=SUM(first!D2:first!D4)'], columns = ['SUM']).to_excel(writer, sheet_name='second')
next_sheet.to_excel(writer, sheet_name='third')
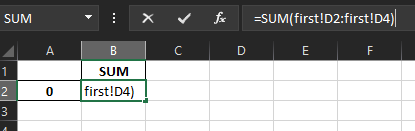
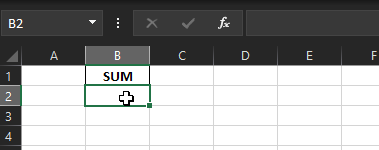
But when I write run this code, the first and second sheet is written as expected, the first one just has the raw data, second one has column SUM and the SUM of values from the first sheet, but the third sheet has only a column name SUM but no values below it.
Second sheet:
Third sheet:
My goal is to be able to write a dataframe with formulas instead of raw values which I would then append to an existing excel file as a new sheet. Where is my mistake in approaching it as an example in third sheet?
I have followed this example.
CodePudding user response:
What happens?
You create an empty dataframe and try to set the column SUM to your value, but there are no rows in your dataframe to operate on. So it only creates the new empty column.
How to fix?
Assign your data with your new column SUM to your empty dataframe:
next_sheet = next_sheet.assign(SUM=['=SUM(first!D2:first!D4)'])
or as already done directly with creating your dataframe:
next_sheet = pd.DataFrame(data = ['=SUM(first!D2:first!D4)'], columns = ['SUM'])
Example
import pandas as pd
next_sheet = pd.DataFrame()
next_sheet = next_sheet.assign(SUM=['=SUM(first!D2:first!D4)'])
with pd.ExcelWriter('test.xlsx', engine="openpyxl", mode="a") as writer:
pd.DataFrame(data = ['=SUM(first!D2:first!D4)'], columns = ['SUM']).to_excel(writer, sheet_name='second')
next_sheet.to_excel(writer, sheet_name='third')