I have a general question about Keras. When training a Artificial Neural Network (e.g. a Multi-Layer-Perceptron or a LSTM) with a split of training, validation and test data (e.g. 70 %, 20 %, 10 %), I would like to know which parameter configuration the trained model is eventually using for predictions?
Here I have an exmaple from a training process with 11 epoch:
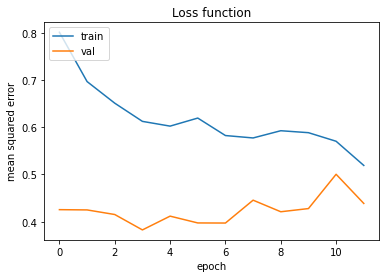
I could think about 3 possible parameter configurations (surely there are also others):
- The configuration that led to the lowest error in the training dataset (which would be after the 11th epoch)
- The configuration after the last epoch (which would the after the 11th epoch, as in 1.)
- The configuration that led to the lowest error in the validation dataset (which would be after the 3rd epoch)
If you just build the model without for example like this:
# Build the model and train it
optimizer_adam = tf.keras.optimizers.Adam(lr= 0.001)
model = keras.models.Sequential([
keras.layers.LSTM(10, return_sequences=True, input_shape=[None, numberOfInputFeatures]),
keras.layers.LSTM(10, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(numberOfOutputNeurons))
])
model.compile(loss="mean_squared_error", optimizer=optimizer_adam, metrics=['mean_absolute_percentage_error'])
history = model.fit(X_train, Y_train, epochs=11, batch_size=10, validation_data=(X_valid, Y_valid))
# Predict the values from the test dataset
Y_pred = model.predict(X_test)
Can you tell me which configuration is used for predicting the values from the test dataset in the line Y_pred = model.predict(X_test)?
CodePudding user response:
It would be the configuration after the last epoch (the 2nd possible configuration that you have mentioned).