I would like to summarize a time series of data by:
- Category - (1. Low, 2. Moderate, 3. Strong, 4. Extreme).
- The start and end times of the run of each Category.
The image below shows a snippet of the data and the desired output.
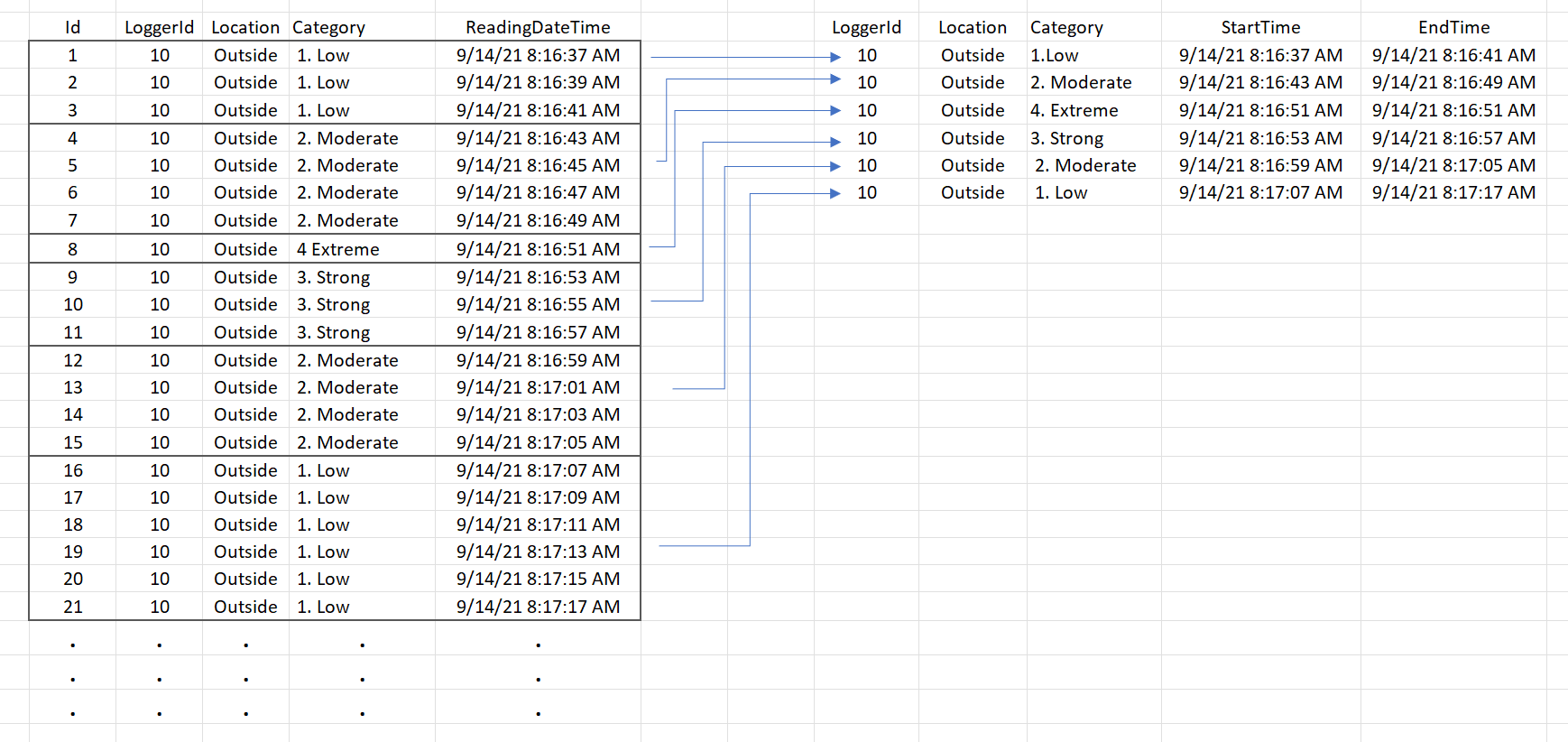
Since the
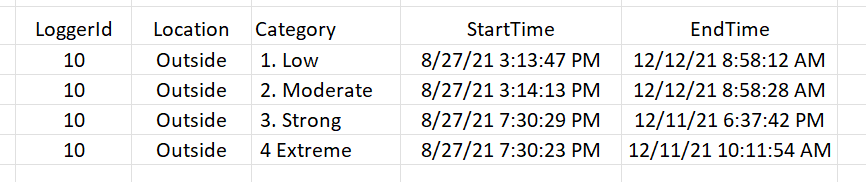
Categories(1. Low, 2. Moderate, 3. Strong, 4. Extreme) repeat throughout the timeline, an approach such as theSELECTbelow will summarize theMINandMAXReadingDateTimevalues over the entire table in four rows.- The minimum and maximum
ReadingDateTimeover all readings in the Low category. - The minimum and maximum
ReadingDateTimeover all readings in the Moderate category. - The minimum and maximum
ReadingDateTimeover all readings in the Strong category. - The minimum and maximum
ReadingDateTimeover all readings in the Extreme category.
- The minimum and maximum
SELECT..
MIN(ReadingDateTime)
,MAX(ReadingDateTime)
FROM CurrentLogger
GROUP BY LoggerId
,Category
ORDER BY LoggerId
,ReadingDateTime
For example:
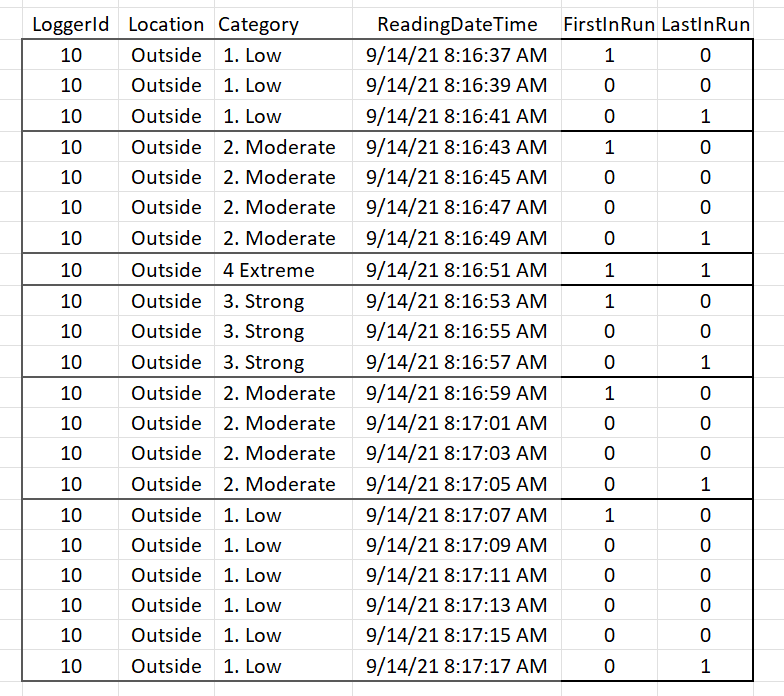
I have one approach, but I am sure there is a much better way. I mark the start and end of runs of Categories by using the SQL LAG and LEAD functions.
SELECT LoggerId
,Location
,Category
,dBDateTime
,FirstInRun = IIF(LAG(dBCategory,1,0) OVER(ORDER BY InstrumentId, dBDateTime)<>dBCategory,1,0)
,LastInRun = IIF(LEAD(dBCategory,1,0) OVER(ORDER BY InstrumentId, dBDateTime)<>dBCategory,1,0)
FROM CurrentLogger
ORDER BY InstrumentId
,dBDateTime
The output is below:
There are several ugly and slow ways to roll this up to the desired output.
My question is:
- Before rolling this up to the desired output, is there a far more obvious way to get the start and end times for each of the consecutive categorical runs?
CodePudding user response:
One way to roll it up is to use the ROW_NUMBER() function to create your groups and then get the MIN/MAX dates for each group. Consider the following:
CREATE TABLE #CurrentLogger(LoggerID int, Location varchar(20),Category varchar(20),ReadingDateTime datetime)
INSERT INTO #CurrentLogger VALUES
(10,'OutSide','1. Low','9/14/21 8:16:37 AM'),
(10,'OutSide','1. Low','9/14/21 8:16:39 AM'),
(10,'OutSide','1. Low','9/14/21 8:16:41 AM'),
(10,'OutSide','2. Moderate','9/14/21 8:16:43 AM'),
(10,'OutSide','2. Moderate','9/14/21 8:16:45 AM'),
(10,'OutSide','2. Moderate','9/14/21 8:16:47 AM'),
(10,'OutSide','2. Moderate','9/14/21 8:16:49 AM'),
(10,'OutSide','4. Extreme','9/14/21 8:16:51 AM'),
(10,'OutSide','3. Strong','9/14/21 8:16:53 AM'),
(10,'OutSide','3. Strong','9/14/21 8:16:55 AM'),
(10,'OutSide','3. Strong','9/14/21 8:16:57 AM'),
(10,'OutSide','2. Moderate','9/14/21 8:16:59 AM'),
(10,'OutSide','2. Moderate','9/14/21 8:17:01 AM'),
(10,'OutSide','2. Moderate','9/14/21 8:17:03 AM'),
(10,'OutSide','2. Moderate','9/14/21 8:17:05 AM'),
(10,'OutSide','1. Low','9/14/21 8:17:07 AM'),
(10,'OutSide','1. Low','9/14/21 8:17:09 AM'),
(10,'OutSide','1. Low','9/14/21 8:17:11 AM'),
(10,'OutSide','1. Low','9/14/21 8:17:13 AM'),
(10,'OutSide','1. Low','9/14/21 8:17:15 AM'),
(10,'OutSide','1. Low','9/14/21 8:17:17 AM');
WITH CTE AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY LoggerID ORDER BY ReadingDateTime)
- ROW_NUMBER() OVER(PARTITION BY LoggerID,Location,Category ORDER BY ReadingDateTime) Grp
FROM #CurrentLogger
)
SELECT LoggerID,Location,Category, MIN(ReadingDateTime) StartDate, MAX(ReadingDateTime) EndDate
FROM CTE
GROUP BY Grp,LoggerID,Location,Category
ORDER BY StartDate