I have a pandas series with data of type tuple as list elements. The length of the tuple is exactly 2 and there are a bunch of NaNs. I am trying to split each list in the tuple into its own column.
import pandas as pd
df = pd.DataFrame({'val': [([1,2,3],[4,5,6]),
([7,8,9],[10,11,12]),
np.nan]
})
Expected Output:
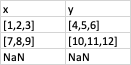
CodePudding user response:
You could also convert the column to a list and cast it to the DataFrame constructor (fill None with np.nan as well):
out = pd.DataFrame(df['val'].tolist(), columns=['x','y']).fillna(np.nan)
Output:
x y
0 [1, 2, 3] [4, 5, 6]
1 [7, 8, 9] [10, 11, 12]
2 NaN NaN
CodePudding user response:
If you know the lenght of tuples are exactly 2, you can do:
df["x"] = df.val.str[0]
df["y"] = df.val.str[1]
print(df[["x", "y"]])
Prints:
x y
0 [1, 2, 3] [4, 5, 6]
1 [7, 8, 9] [10, 11, 12]
2 NaN NaN
CodePudding user response:
One way using pandas.Series.apply:
new_df = df["val"].apply(pd.Series)
print(new_df)
Output:
0 1
0 [1, 2, 3] [4, 5, 6]
1 [7, 8, 9] [10, 11, 12]
2 NaN NaN