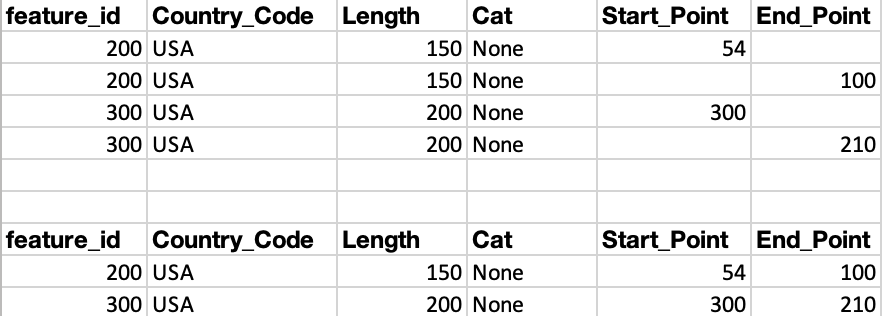
I have a single data frame and every row is duplicated except for two values. In all cases the corresponding duplicate has a blank value in the corresponding row. I want to 'collapse' these rows and fill in the blanks.
In the example below, I want to collapse the top DataFrame to mirror the bottom
CodePudding user response:
You can use groupby first; first skips over NaN values by default:
collapsed_df = df.groupby("feature_id").first().reset_index()
If the empty spaces are not NaN values, probably will want to fill them with NaN first:
df = df.replace('', np.nan)