I have the following dataset:
X <- data.frame(PERMNO = c(10001,10002,10003,10001,10002,10003),
Date = c("Nov 2021","Nov 2021","Nov 2021","Dec 2021","Dec 2021","Dec 2021"),
ME = c(100,95,110,110,115,108),
IVOL = c(1,1.1,0.8,0.7,1,2.1),
C = c(NA, 2, 3,NA, 4, 1.5))
For firm 10001, the C is missing. I want to fill C, each month, by matching C from other firms by using the firm with non-missing C that minimizes the euclidean distance of the ranked ME and the ranked IVOL with the missing firm:
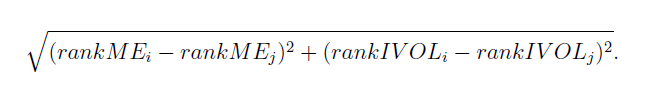
X in my application has more PERMNOs and a longer time frame, and multiple firms may have C missing. My question is how to code this efficiently in R.
Taking the ranks is straight forward by using rank() and the Euclidean distance can be calculated using outer() if I am correct. However, I struggle with making the pairs of firm i and j and then selecting the minimum distance and subsequently match C from firm j to the missing C for firm i.
CodePudding user response:
A data.table solution using colMins from the Rfast package.
library(data.table)
X <- data.frame(PERMNO = c(10001,10002,10003,10001,10002,10003),
Date = c("Nov 2021","Nov 2021","Nov 2021","Dec 2021","Dec 2021","Dec 2021"),
ME = c(100,95,110,110,115,108),
IVOL = c(1,1.1,0.8,0.7,1,2.1),
C = c(NA, 2, 3, NA, 4, 1.5))
fFillNA <- function(C, ME, IVOL) {
idxNA <- which(is.na(C))
C[idxNA] <- C[-idxNA][Rfast::colMins(outer(ME[-idxNA], ME[idxNA], "-")^2 outer(IVOL[-idxNA], IVOL[idxNA], "-")^2)]
C
}
setDT(X)[, C := if(anyNA(C)) fFillNA(C, ME, IVOL), by = "Date"]
X
#> PERMNO Date ME IVOL C
#> 1: 10001 Nov 2021 100 1.0 2.0
#> 2: 10002 Nov 2021 95 1.1 2.0
#> 3: 10003 Nov 2021 110 0.8 3.0
#> 4: 10001 Dec 2021 110 0.7 1.5
#> 5: 10002 Dec 2021 115 1.0 4.0
#> 6: 10003 Dec 2021 108 2.1 1.5
No need to take the square root to get the index of the minimum distance. Also, notice that because of relative size, ME impacts the distance calculation much more than IVOL, at least for the example dataset. Maybe consider normalizing ME and IVOL in the distance calculation.
CodePudding user response:
Maybe this helps:
library(tidyverse)
X <- data.frame(
PERMNO = c(10001, 10002, 10003, 10001, 10002, 10003),
Date = c("Nov 2021", "Nov 2021", "Nov 2021", "Dec 2021", "Dec 2021", "Dec 2021"),
ME = c(100, 95, 110, 110, 115, 108),
IVOL = c(1, 1.1, 0.8, 0.7, 1, 2.1),
C = c(NA, 2, 3, NA, 4, 1.5)
) %>% as_tibble()
X
#> # A tibble: 6 x 5
#> PERMNO Date ME IVOL C
#> <dbl> <chr> <dbl> <dbl> <dbl>
#> 1 10001 Nov 2021 100 1 NA
#> 2 10002 Nov 2021 95 1.1 2
#> 3 10003 Nov 2021 110 0.8 3
#> 4 10001 Dec 2021 110 0.7 NA
#> 5 10002 Dec 2021 115 1 4
#> 6 10003 Dec 2021 108 2.1 1.5
imputations <-
X %>%
rename_all(~ paste0(.x, ".1")) %>%
expand_grid(X %>% rename_all(~ paste0(., ".2"))) %>%
mutate(
dist = sqrt((rank(ME.1) - rank(ME.2))**2 (rank(IVOL.1) - rank(IVOL.2))**2)
) %>%
group_by(PERMNO.1) %>%
filter(PERMNO.1 != PERMNO.2) %>%
arrange(dist) %>%
slice(1) %>%
ungroup() %>%
transmute(
PERMNO = PERMNO.1,
imputed.C = case_when(
!is.na(C.1) ~ C.1,
!is.na(C.2) ~ C.2
)
)
imputations
#> # A tibble: 3 x 2
#> PERMNO imputed.C
#> <dbl> <dbl>
#> 1 10001 3
#> 2 10002 2
#> 3 10003 3
X %>%
left_join(imputations) %>%
mutate(C = ifelse(is.na(C), imputed.C, C)) %>%
select(-imputed.C)
#> Joining, by = "PERMNO"
#> # A tibble: 6 x 5
#> PERMNO Date ME IVOL C
#> <dbl> <chr> <dbl> <dbl> <dbl>
#> 1 10001 Nov 2021 100 1 3
#> 2 10002 Nov 2021 95 1.1 2
#> 3 10003 Nov 2021 110 0.8 3
#> 4 10001 Dec 2021 110 0.7 3
#> 5 10002 Dec 2021 115 1 4
#> 6 10003 Dec 2021 108 2.1 1.5
Created on 2022-02-18 by the reprex package (v2.0.0)