Junior dev here.
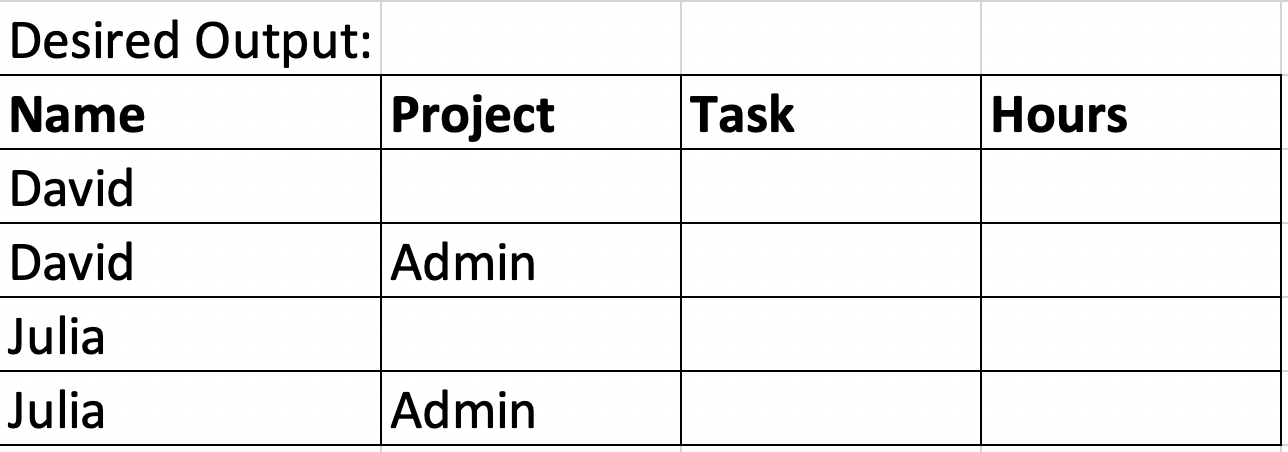
Goal: Implement a second autogenerated row with one of the projects prefilled out. The first row is blank.
Requirements:
- The first row of each resource will remain blank.
- The second row will have a pre-generated project name called "Admin".
- The rows of each resource must be next to each other.
- Sort the "Name" row by ASC order.
- This must be applied to the entire dataset (~900 resources, demo df created for illustration of assistance).
I think I have to do something with a lamda function but I'm not clear on how to fill only 1 row from each resource.
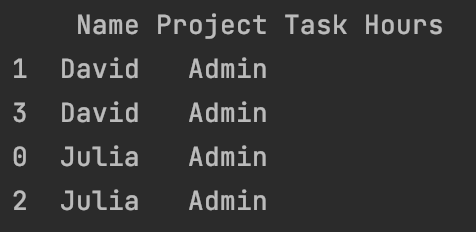
Current Output: I have the table in a pandas Dataframe. The console output is what I have currently.
Here's what I have in the script.
import pandas as pd
# Demo DF only
df1 = {
'Name': ['Julia', 'David'],
'Project': ['',''],
'Task': ['',''],
'Hours': ['','']
}
df1 = pd.DataFrame(df1, columns=['Name', 'Project', 'Task','Hours'])
df1 = df1.assign(Project="Admin")
df_repeated = pd.concat([df1]*2, ignore_index=True)
df_repeated = df_repeated.sort_values(by=['Name'], ascending=True)
print(df_repeated)
CodePudding user response:
pd.concat([df1, df1.assign(Project="Admin")],
ignore_index=True).sort_values(["Name", "Project"])
# Name Project Task Hours
# 1 David
# 3 David Admin
# 0 Julia
# 2 Julia Admin
CodePudding user response:
You could use numpy's function "where" to either add the "Admin" in every other row:
df1 = pd.DataFrame(df1)
df_repeated = pd.concat([df1]*2, ignore_index=True)
df_repeated = df_repeated.sort_values(by=['Name'], ascending=True, ignore_index=True)
df_repeated['Project'] = np.where(df_repeated.index % 2, 'Admin', '')