I think the code below is OK but seems to clumsy. Basically, I want to go from here:
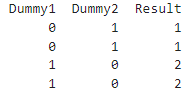
to here:
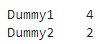
Basically adding column Result if the dummy column is 1. Hope this makes sense?
data = {'Dummy1':[0, 0, 1, 1],
'Dummy2':[1, 1, 0, 0],
'Result':[1, 1, 2, 2]}
haves = pd.DataFrame(data)
print(haves)
melted = pd.melt(haves, id_vars=['Result'])
melted = melted.loc[melted["value"] > 0]
print(melted)
wants = melted.groupby(["variable"])["Result"].sum()
print(wants)
CodePudding user response:
No need to melt, perform a simple multiplication and sum:
wants = haves.drop('Result', axis=1).mul(haves['Result'], axis=0).sum()
output:
Dummy1 4
Dummy2 2
dtype: int64
Intermediate:
>>> haves.drop('Result', axis=1).mul(haves['Result'], axis=0)
Dummy1 Dummy2
0 0 1
1 0 1
2 2 0
3 2 0
Shorter variant
Warning: this mutates the original dataframe, which will lose the 'Result' column.
wants = haves.mul(haves.pop('Result'), axis=0).sum()