I am trying to upload Google n-gram word frequency data into a dataframe.
Dataset can be found here: 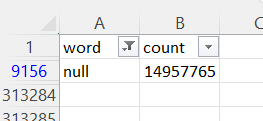
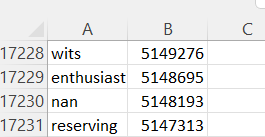
This is how I am uploading the data
my_freq_df = pd.read_csv('ngram_freq_dict.csv', dtype = {"word": str, "count": np.int32} )
my_freq_df['word'] = my_freq_df['word'].astype("string")
Unfortunately, when I try to check if those words were loaded as strings, I get that they weren't
count = 0
for index, row in my_freq_df.iterrows():
count = 1
try:
len(row['word'])
except:
print(row['word'])
print(count)
print("****____*****")
We can see the image of the output of the try, except and we can see that I cant calculate the length of the words "nan" and "null". Both words are being read as NA.
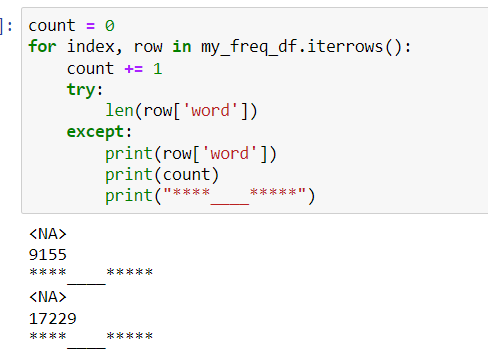
How do I fix this?
CodePudding user response:
Pandas treats a certain set of values as "NA" by default, but you can explicitly tell it to ignore those defaults with keep_default_na=False. "null" and "nan" both happen to be in that list!
my_freq_df = pd.read_csv(
'ngram_freq_dict.csv',
dtype = {"word": str, "count": np.int32},
keep_default_na=False
)
As of today, the complete set of strings that it treats as NA by default is:
[
"", "#N/A", "#N/A N/A", "#NA", "-1.#IND", "-1.#QNAN", "-NaN",
"-nan", "1.#IND", "1.#QNAN", "<NA>", "N/A", "NA", "NULL",
"NaN", "n/a", "nan", "null"
]
https://pandas.pydata.org/docs/reference/api/pandas.read_csv.html