I have electrical consumption data between 2016-2019. The data was recorded every 30 minutes for 4 years. There is no data between 13/03/2019 - 31/03/209.
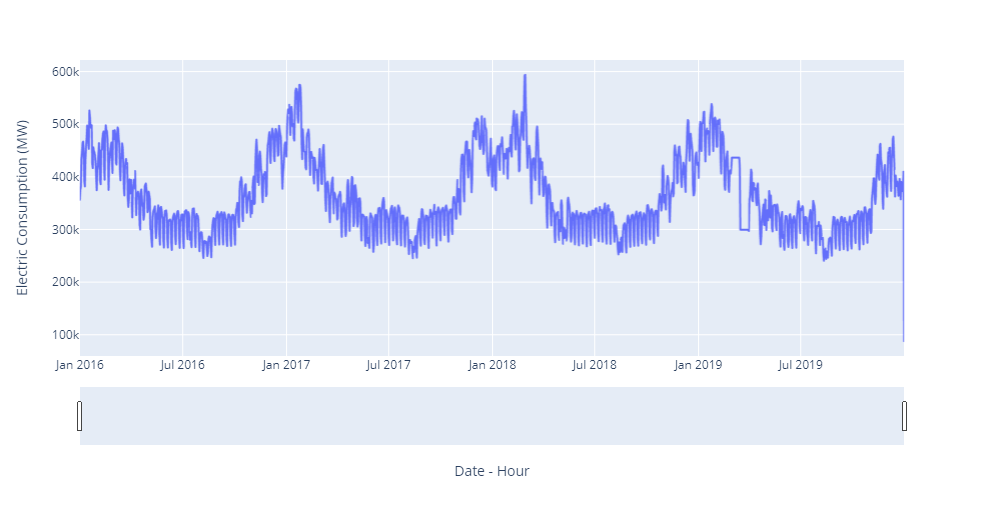
- I want to ask how I can detect this miss by coding without visualization because I have 12 countries and they may have such missing values in other months and they are not visible. (Detect if there is a miss for more than 3 consecutive days). Thank you for your help!
This is the data:
Country Code Electric Consumption (MW)
Date (index)
2016-01-01 84 354642.0
2016-01-02 84 376207.0
2016-01-03 84 381534.0
2016-01-04 84 435561.0
2016-01-05 84 447820.0
... ... ...
2019-12-27 12 374340.0
2019-12-28 12 372761.0
2019-12-29 12 379411.0
2019-12-30 12 416044.0
2019-12-31 12 87519.0
CodePudding user response:
Here is a way to identify the 3 day gaps and fill them. Note that this is working on each unique country code. You can save the final_dfs with a list and use pd.concat() if you need to get them back together again.
import pandas as pd
import numpy as np
df = pd.DataFrame({'Country Code': {'2016-01-01': 84,
'2016-01-02': 84,
'2016-01-03': 84,
'2016-01-04': 84,
'2016-01-05': 84,
'2019-12-27': 12,
'2019-12-28': 12,
'2019-12-29': 12,
'2019-12-30': 12,
'2019-12-31': 12},
'Electric Consumption (MW)': {'2016-01-01': 354642.0,
'2016-01-02': 376207.0,
'2016-01-03': 381534.0,
'2016-01-04': 435561.0,
'2016-01-05': 447820.0,
'2019-12-27': 374340.0,
'2019-12-28': 372761.0,
'2019-12-29': 379411.0,
'2019-12-30': 416044.0,
'2019-12-31': 87519.0}})
# change index value for fake gap
df.index = ['2016-01-01', '2016-01-02', '2016-01-03', '2016-01-04',
'2016-01-05', '2019-12-27', '2019-12-28',
'2019-12-29', '2019-12-30', '2020-01-06']
#convert object dates to datetime
df.index = pd.to_datetime(df.index)
for g in df['Country Code'].unique():
# look at each unique country
country_slice = df.loc[df['Country Code'] == g]
# use timedelta to identify 3 day gaps
country_slice['Three Day Gap'] = country_slice.index.to_series().diff() > pd.Timedelta('3d')
# create a new index with previous min and max
idx = pd.date_range(country_slice.index.min(), country_slice.index.max())
s = country_slice['Electric Consumption (MW)']
s.index = pd.DatetimeIndex(s.index)
# this gives us a series with new rows and nans for the missing dates
s = s.reindex(idx, fill_value=np.nan)
# join the old data back to nex index
country_slice_join = country_slice.join(s, how='outer', lsuffix='L')
# now we can interpolate as missing dates are new rows
country_slice_join['interpolate'] = country_slice_join['Electric Consumption (MW)'].interpolate(method='linear', axis=0)
country_slice_join['Country Code'] = country_slice_join['Country Code'].ffill()
# remove temp columns
final_df = country_slice_join[['Country Code', 'interpolate']]
final_df.columns = ['Country Code', 'Electric Consumption (MW)']
Example country_slice_join output before final_df:
Country Code Electric Consumption (MW)L Three Day Gap Electric Consumption (MW) interpolate
2019-12-27 12.0 374340.0 False 374340.0 374340.000000
2019-12-28 12.0 372761.0 False 372761.0 372761.000000
2019-12-29 12.0 379411.0 False 379411.0 379411.000000
2019-12-30 12.0 416044.0 False 416044.0 416044.000000
2019-12-31 12.0 NaN NaN NaN 369111.857143
2020-01-01 12.0 NaN NaN NaN 322179.714286
2020-01-02 12.0 NaN NaN NaN 275247.571429
2020-01-03 12.0 NaN NaN NaN 228315.428571
2020-01-04 12.0 NaN NaN NaN 181383.285714
2020-01-05 12.0 NaN NaN NaN 134451.142857
2020-01-06 12.0 87519.0 True 87519.0 87519.000000
Example final_df output without temporary columns:
Country Code Electric Consumption (MW)
2019-12-27 12.0 374340.000000
2019-12-28 12.0 372761.000000
2019-12-29 12.0 379411.000000
2019-12-30 12.0 416044.000000
2019-12-31 12.0 369111.857143
2020-01-01 12.0 322179.714286
2020-01-02 12.0 275247.571429
2020-01-03 12.0 228315.428571
2020-01-04 12.0 181383.285714
2020-01-05 12.0 134451.142857
2020-01-06 12.0 87519.000000
CodePudding user response:
You are the best judge in this situation, and you'll have to decide based on what are the best results for what you're trying to do. By the way, you are trying to fill missing values and not to identify them.
There are a some options inside the DataFrame.interpolate() functions and you can find that here.
There are other options that you don't actually do anything with the data, you just copy values from adjacent rows, like DataFrame.ffill() and DataFrame.bfill().