My dataset contains categorical values stored as numbers. Below you can see how is look like my data.
data = {'id':['1','2','3','4','5'],
'nc':['01', '1.0', '2.0', '13.0',"B"]}
df = pd.DataFrame(data, columns = ['id','nc'])
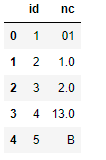
Now I want to join this table with a table who have categorical data (e.g 01,02,03 etc.) but I can't because values are not the same.
So can anybody help me how to modify this column or in other words separate values by "." and adding zero for numbers below 10, like the table below:
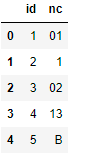
I try with this line of code but is not working
df["nc1"]= df['nc'].str.split(".", expand = True)
CodePudding user response:
We can try with Series.str.len and Series.str.rstrp
df['nc'] = df['nc'].str.rstrip('.0')
df.loc[df['nc'].str.len().le(1) & df['nc'].str.isnumeric(), 'nc'] = '0' df['nc']
print(df)
id nc
0 1 01
1 2 01
2 3 02
3 4 13
4 5 B
CodePudding user response:
The logic is not fully clear, by changing 2.0 numbers into 02 is quite easy with a regex:
df['nc'] = df['nc'].str.replace(r'^(\d )(\.0 )$', lambda m: m.group(1).zfill(2))
output (here as a new column nc2 for clarity):
id nc nc2
0 1 01 01
1 2 1.0 01
2 3 2.0 02
3 4 13.0 13
4 5 B B