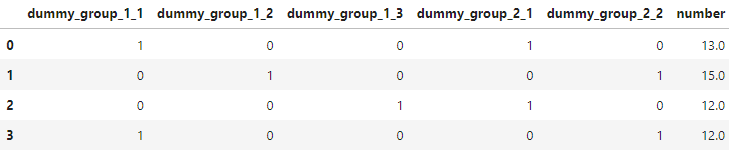
I have these simplified data:
data = {'dummy_group_1_1':[1, 0, 0, 1],
'dummy_group_1_2':[0, 1, 0, 0],
'dummy_group_1_3':[0, 0, 1, 0],
'dummy_group_2_1':[1, 0, 1, 0],
'dummy_group_2_2':[0, 1, 0, 1],
'number':[13.0, 15.0, 12.0, 12.0]}
haves = pd.DataFrame(data)
haves
Firstly, I would like to collapse columns horizontally for each "dummy variable group" dummy_group_1 and dummy_group_2 where the entry is 1. The result would be:
dummy_group_1, dummy_group_2, number
1, 1, 13
2, 2, 15
3, 1, 12
1, 2, 12
There are many of these columns and I guess one could use something along those lines: haves.columns.str.startswith('dummy_group_1')? I would not know what to do to achieve this sorry ...
Having these intermediate results, I would like to get the dummy_group_1 and dummy_group_2 combination for the max value of "number" for the combination (tie situations take any). The results would be:
dummy_group_1, dummy_group_2, max
1, 1, 13
2, 2, 15
3, 1, 12
Is this possible?
PS:
Here is my miserable long wounded way of getting to step 1:
data = {'dummy_group_1_1':[1, 0, 0, 1],
'dummy_group_1_2':[0, 1, 0, 0],
'dummy_group_1_3':[0, 0, 1, 0],
'dummy_group_2_1':[1, 0, 1, 0],
'dummy_group_2_2':[0, 1, 0, 1],
'number':[13.0, 15.0, 12.0, 12.0]}
haves = pd.DataFrame(data)
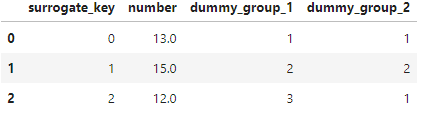
haves['surrogate_key'] = haves.reset_index().index
haves
group_1 = haves.loc[:, haves.columns.str.startswith('dummy_group_1') | haves.columns.str.startswith('surrogate_key')]
group_1 = pd.melt(group_1, id_vars=['surrogate_key']).query("value > 0")
group_1.drop('value', axis=1, inplace=True)
group_1['variable'] = group_1['variable'].str.replace('dummy_group_1_', '')
group_1.columns = group_1.columns.str.replace('variable', 'dummy_group_1')
group_2 = haves.loc[:, haves.columns.str.startswith('dummy_group_2') | haves.columns.str.startswith('surrogate_key')]
group_2 = pd.melt(group_2, id_vars=['surrogate_key']).query("value > 0")
group_2.drop('value', axis=1, inplace=True)
group_2['variable'] = group_2['variable'].str.replace('dummy_group_2_', '')
group_2.columns = group_2.columns.str.replace('variable', 'dummy_group_2')
numbers = haves[['surrogate_key', 'number']]
step1_data = pd.merge(numbers, group_1, how='inner', left_on=['surrogate_key'], right_on = ['surrogate_key'])
step1_data = pd.merge(step1_data, group_2, how='inner', left_on=['surrogate_key'], right_on = ['surrogate_key'])
step1_data
Given parts of richardec's answer I can get to the final results doing:
step1_data.loc[step1_data.groupby('dummy_group_1')['number'].idxmax()]
which gives:
CodePudding user response:
Try something like this:
cols = ['number']
tmp = haves[haves.columns.difference(cols)]
tmp = pd.concat([tmp.apply(lambda col: col.map({1: int(col.name.split('_')[3])})).groupby(tmp.columns.str.split('_').str[2], axis=1).bfill().dropna(axis=1).astype(int), haves[cols]], axis=1)
tmp = tmp.loc[tmp.groupby('dummy_group_1_1')['number'].idxmax()]
Output:
>>> tmp
dummy_group_1_1 dummy_group_2_1 number
0 1 1 13.0
1 2 2 15.0
2 3 1 12.0