Here is an example code to demonstrate my problem:
import numpy as np
import pandas as pd
np.random.seed(10)
df = pd.DataFrame(np.random.randint(0,10,size=(100, 2)), columns=list('xy'))
df
x y
0 9 4
1 0 1
2 9 0
3 1 8
4 9 0
... ... ...
95 0 4
96 6 4
97 9 8
98 0 7
99 1 7
groups = df.groupby(['x'])
groups.size()
x
0 11
1 12
2 15
3 13
4 14
5 5
6 6
7 9
8 5
9 10
dtype: int64
How can I access the x-values as a column and the aggregated y-values as a second column to plot x versus y?
CodePudding user response:
Two options.
- Use
reset_index():
groups = df.groupby(['x']).size().reset_index(name='size')
- Add
as_index=Falsetogroupby:
groups = df.groupby(['x'], as_index=False).size()
Output for both:
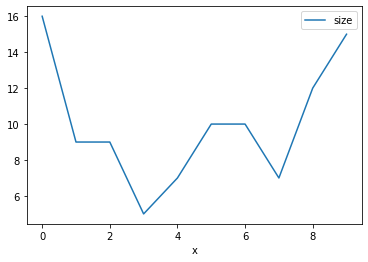
>>> groups
x size
0 0 16
1 1 9
2 2 9
3 3 5
4 4 7
5 5 10
6 6 10
7 7 7
8 8 12
9 9 15
CodePudding user response:
IIUC, use as_index=False:
groups = df.groupby(['x'], as_index=False)
out = groups.size()
out.plot(x='x', y='size')
If you only want to plot, you can also keep the x as index:
df.groupby(['x']).size().plot()
output:
x size
0 0 16
1 1 9
2 2 9
3 3 5
4 4 7
5 5 10
6 6 10
7 7 7
8 8 12
9 9 15