I want to see the fitted values by variable while still taking into account all other variables in the model. I would describe these as partial/marginal fitted values. I have a toy example below. This dataset is built into R. Is this possible?
Seatbelts <- data.frame(Seatbelts)
head(Seatbelts)
Seatbelts<-Seatbelts[complete.cases(Seatbelts),]
## 75% of the sample size
smp_size <- floor(0.75 * nrow(Seatbelts))
## set the seed to make your partition reproducible
set.seed(123)
train_ind <- sample(seq_len(nrow(Seatbelts)), size = smp_size)
train <- Seatbelts[train_ind, ]
test <- Seatbelts[-train_ind, ]
# glm()
m1 <- glm(DriversKilled ~ front rear kms PetrolPrice VanKilled law,
family=poisson(link = "log"),
data=train)
fitted(m1)
CodePudding user response:
Here you get the values of the variables with the fitted value of the glm model in a dataframe:
data.frame(front = train$front, rear = train$rear, kms = train$kms,
PetrolPrice = train$PetrolPrice, VanKilled = train$VanKilled,
law = train$law, Fitted = fitted(m1))
CodePudding user response:
I'm not sure, but I think you're looking for an effects plot (or the corresponding data).
library(effects)
plot(allEffects(m1))
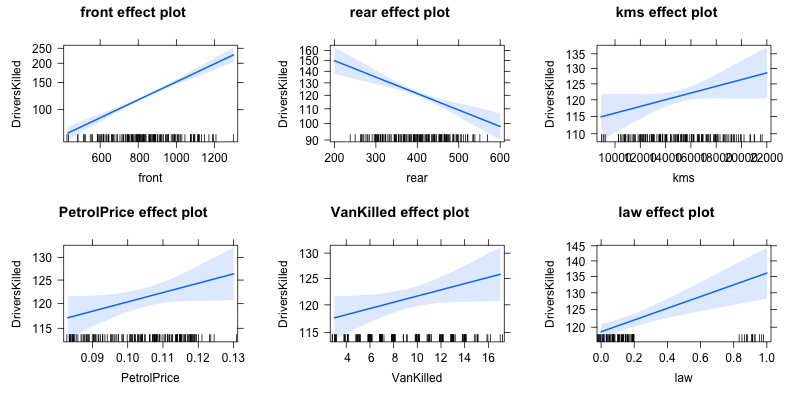
To get the specific values, you could use (e.g.)as.data.frame(allEffects(m1)) (which returns a list of data frames, one for each predictor variable).
The emmeans package has similar/overlapping functionality.