I have a scenario to convert a field of data type varachar 03/28 8:00-7:30 03/29 8:00-7:30 03/30 8:00-6:00 04/02 8:00-7:30 04/03 8:00-7:30 04/04 8:00-7:30 04/05 8:00-7:30 04/06 8:00-7:30 04/07 8:00-6:00 04/09 8:00-7:30 04/10 8:00-7:30 04/11 8:00-7:30 04/12 8:00-7:30 04/13 8:00-7:30 04/14 8:00-3:00
into an array using sql or power BI or excel using power query?
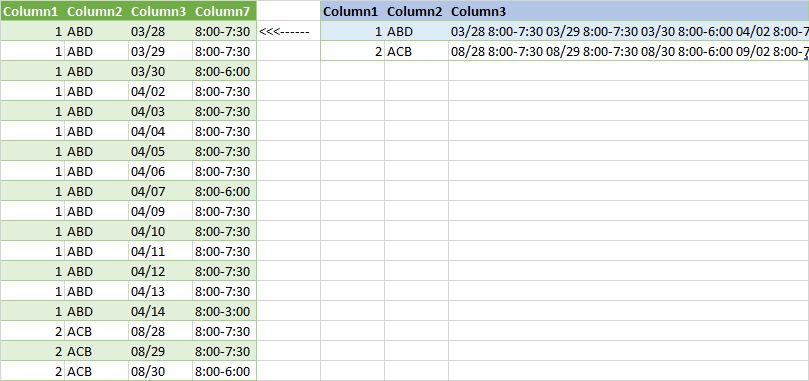
Data now looks like
Emp_ID Emp_name date_hrs_operation
1 ABD "03/28 8:00-7:30 03/29 8:00-7:30 03/30 8:00-6:00 04/02 8:00-7:30 04/03 8:00-7:30 04/04 8:00-7:30 04/05 8:00-7:30 04/06 8:00-7:30 04/07 8:00-6:00 04/09 8:00-7:30 04/10 8:00-7:30 04/11 8:00-7:30
04/12 8:00-7:30 04/13 8:00-7:30 04/14 8:00-3:00"
I need to be in this format,
Emp_ID Emp_Name date_hrs_operation
1 ABD 03/28 8:00-7:30
1 ABD 03/29 8:00-7:30
1 ABD 03/30 8:00-6:00
1 ABD 04/02 8:00-7:30
etc.. By any method can I achieve this?
Thanks in advance!!
CodePudding user response:
Im powerquery, if you have that long string in a column, the below code will split it in the desired method
Basically ... (a) split by space (b) add index (c) modify index to show 0/1 every other row using Number.Mod (d) filter for 0 and combine that column with a filter for 1 (e) remove extra columns (f) rename [not done here]
sample code to transform blue on right to green on left:
you can click select the two columns and merge them if you want
let Source = Excel.CurrentWorkbook(){[Name="Table1"]}[Content],
#"Split Column by Delimiter" = Table.ExpandListColumn(Table.TransformColumns(Source, {{"Column3", Splitter.SplitTextByDelimiter(" ", QuoteStyle.Csv), let itemType = (type nullable text) meta [Serialized.Text = true] in type {itemType}}}), "Column3"),
#"Added Index" = Table.AddIndexColumn(#"Split Column by Delimiter", "Index", 0, 1, Int64.Type),
#"Index modulo" = Table.TransformColumns(#"Added Index",{{"Index", each Number.Mod(_,2), Int64.Type}}),
Part1= Table.ToColumns(Table.SelectRows(#"Index modulo", each ([Index] = 0))),
Part2= Table.ToColumns(Table.SelectRows(#"Index modulo", each ([Index] = 1))),
combined=Table.FromColumns(Part1&Part2),
#"Removed Columns" = Table.RemoveColumns(combined,{"Column4", "Column5", "Column6", "Column8"})
in #"Removed Columns"
optional merging of the two columns, use this ending instead:
#"Removed Columns" = Table.RemoveColumns(combined,{"Column4", "Column5", "Column6", "Column8"}),
#"Merged Columns" = Table.CombineColumns(#"Removed Columns",{"Column3", "Column7"},Combiner.CombineTextByDelimiter(" ", QuoteStyle.None),"Merged")
in #"Merged Columns"
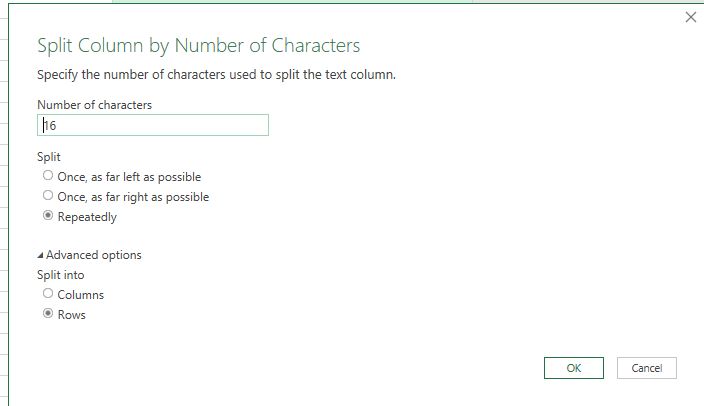
For a different, single step solution, right click ... split column .. by number of positions. Depends on if you can have the time data always have format hh:mm instead of h:mm before noon and hh:mm after noon. For the sample data, which only has h:mm, using 16 characters works in a single step
CodePudding user response:
One more method by using tokenization via XML/XQuery and mod operator.
SQL
-- DDL and sample data population, start
DECLARE @tbl TABLE (ID INT IDENTITY PRIMARY KEY, Emp_ID INT, Emp_name VARCHAR(20), date_hrs_operation VARCHAR(1024));
INSERT INTO @tbl (Emp_ID, Emp_name, date_hrs_operation) VALUES
(1, 'ABD', '03/28 8:00-7:30 03/29 8:00-7:30 03/30 8:00-6:00 04/02 8:00-7:30 04/03 8:00-7:30 04/04 8:00-7:30 04/05 8:00-7:30 04/06 8:00-7:30 04/07 8:00-6:00 04/09 8:00-7:30 04/10 8:00-7:30 04/11 8:00-7:30 04/12 8:00-7:30 04/13 8:00-7:30 04/14 8:00-3:00');
-- DDL and sample data population, end
DECLARE @separator CHAR(1) = SPACE(1);
SELECT Emp_ID, Emp_name
, date_hrs_operation = t.c.value('(./text())[1]', 'VARCHAR(30)') ' '
t.c.value('(/root/*[sql:column("seq.pos")]/text())[1]', 'VARCHAR(30)')
--, seq.pos -- just to see
FROM @tbl
CROSS APPLY (SELECT TRY_CAST('<root><r><![CDATA['
REPLACE(date_hrs_operation, @separator, ']]></r><r><![CDATA[')
']]></r></root>' AS XML)) AS t1(c)
CROSS APPLY t1.c.nodes('/root/*[position() mod 2 = 1]') AS t(c)
CROSS APPLY (SELECT t.c.value('let $n := . return count(/root/*[. << $n[1]]) 2','INT') AS pos
) AS seq;
Output
-------- ---------- --------------------
| Emp_ID | Emp_name | date_hrs_operation |
-------- ---------- --------------------
| 1 | ABD | 03/28 8:00-7:30 |
| 1 | ABD | 03/29 8:00-7:30 |
| 1 | ABD | 03/30 8:00-6:00 |
| 1 | ABD | 04/02 8:00-7:30 |
| 1 | ABD | 04/03 8:00-7:30 |
| 1 | ABD | 04/04 8:00-7:30 |
| 1 | ABD | 04/05 8:00-7:30 |
| 1 | ABD | 04/06 8:00-7:30 |
| 1 | ABD | 04/07 8:00-6:00 |
| 1 | ABD | 04/09 8:00-7:30 |
| 1 | ABD | 04/10 8:00-7:30 |
| 1 | ABD | 04/11 8:00-7:30 |
| 1 | ABD | 04/12 8:00-7:30 |
| 1 | ABD | 04/13 8:00-7:30 |
| 1 | ABD | 04/14 8:00-3:00 |
-------- ---------- --------------------
CodePudding user response:
Another option in SQL Server is to use an ad-hoc tally/numbers table in concert with a CROSS APPLY
Example
Select A.Emp_ID
,A.Emp_name
,C.*
From YourTable A
Cross Join (Select Top 50 N=-1 Row_Number() Over (Order By (Select NULL)) From master..spt_values n1 ) B
Cross Apply ( values (substring([date_hrs_operation],(N*16) 1,16)) )C(date_hrs_operation)
Where C.date_hrs_operation<>''
Results
Emp_ID Emp_name date_hrs_operation
1 ABD 03/28 8:00-7:30
1 ABD 03/29 8:00-7:30
1 ABD 03/30 8:00-6:00
1 ABD 04/02 8:00-7:30
1 ABD 04/03 8:00-7:30
1 ABD 04/04 8:00-7:30
1 ABD 04/05 8:00-7:30
1 ABD 04/06 8:00-7:30
1 ABD 04/07 8:00-6:00
1 ABD 04/09 8:00-7:30
1 ABD 04/10 8:00-7:30
1 ABD 04/11 8:00-7:30
1 ABD 04/12 8:00-7:30
1 ABD 04/13 8:00-7:30
1 ABD 04/14 8:00-3:00
EDIT - Rather than a CROSS JOIN you can use an explicit join and remove the WHERE
...
Join (Select Top 100 N=-1 Row_Number() Over (Order By (Select NULL)) From master..spt_values n1, master..spt_values n2 ) B on N<=len([date_hrs_operation])/16
...