I have this pandas Dataframe:
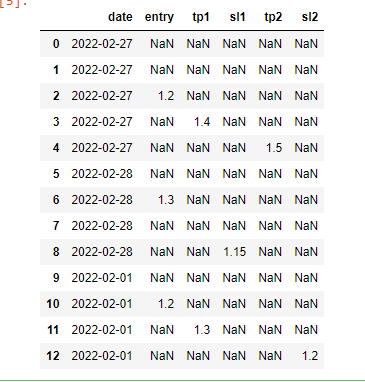
My goal is to perform some addictions and substractions based on culumns value conditions, and store the results inside a new column "pl",
This is the Dataframe I want to have:

The first non-NaN value will be necessarly in the "entry" column,
First scenario: I want that, if the next non-NaN value (after a non-NaN inside "entry" and then a non-NaN inside "tp1") is contained inside "tp2" column, then do this operation: (tp1 - entry) (tp2 - entry)
Second scenario: I want that, if the next non-NaN value (after entry) is contained inside the column "sl1" then do this operation: sl1 - entry.
Third scenario: I want that, if the next non-NaN value (after entry) is contained inside the column "tp1" and there's a non-NaN value inside the column "sl2" then do this operation: tp1 - entry.
This is my code:
import pandas as pd
tbl = {"date" :["2022-02-27", "2022-02-27", "2022-02-27", "2022-02-27", "2022-02-27",
"2022-02-28", "2022-02-28","2022-02-28", "2022-02-28", "2022-02-01",
"2022-02-01", "2022-02-01", "2022-02-01"],
"entry" : ["NaN", "NaN", 1.2, "NaN", "NaN","NaN", 1.3, "NaN", "NaN", "NaN", 1.2, "NaN",
"NaN",],
"tp1" : ["NaN", "NaN", "NaN", 1.4, "NaN", "NaN", "NaN", "NaN", "NaN", "NaN", "NaN",
1.3, "NaN"],
"sl1" : ["NaN", "NaN", "NaN", "NaN", "NaN", "NaN", "NaN", "NaN", 1.15, "NaN", "NaN",
"NaN", "NaN"],
"tp2" : ["NaN", "NaN", "NaN", "NaN", 1.5, "NaN","NaN", "NaN", "NaN", "NaN", "NaN",
"NaN", "NaN"],
"sl2" : ["NaN", "NaN", "NaN", "NaN", "NaN", "NaN","NaN", "NaN", "NaN", "NaN", "NaN",
"NaN", 1.2]}
df = pd.DataFrame(tbl)
df = df.replace('NaN', float('nan'))
############## This is the way i'm trying to achive what i want:#########
#this code will only make tp1 - entry, or sl1 - entry, but it's wrong
#bacause it's made based on a dataframe without "sl2,tp2" consideration
group = df['date']
s1 = df['tp1'].fillna(df['sl1']).groupby(group).bfill()
s2 = df['entry'].groupby(group).bfill()
df.loc[~group.duplicated(), 'pl'] = s1-s2
I'm blocked here, I don't understand how to code the other conditions, Any ideas?
Edit The first value inside pl column is wrong, it should be 0.5. Not 0.20
CodePudding user response:
you can take advatage of numpy ravel() function to flatten the df without the date column:
import pandas as pd
import numpy as np
tbl = {"date" :["2022-02-27", "2022-02-27", "2022-02-27", "2022-02-27", "2022-02-27",
"2022-02-28", "2022-02-28","2022-02-28", "2022-02-28", "2022-02-01",
"2022-02-01", "2022-02-01", "2022-02-01"],
"entry" : ["NaN", "NaN", 1.2, "NaN", "NaN","NaN", 1.3, "NaN", "NaN", "NaN", 1.2, "NaN",
"NaN",],
"tp1" : ["NaN", "NaN", "NaN", 1.4, "NaN", "NaN", "NaN", "NaN", "NaN", "NaN", "NaN",
1.3, "NaN"],
"sl1" : ["NaN", "NaN", "NaN", "NaN", "NaN", "NaN", "NaN", "NaN", 1.15, "NaN", "NaN",
"NaN", "NaN"],
"tp2" : ["NaN", "NaN", "NaN", "NaN", 1.5, "NaN","NaN", "NaN", "NaN", "NaN", "NaN",
"NaN", "NaN"],
"sl2" : ["NaN", "NaN", "NaN", "NaN", "NaN", "NaN","NaN", "NaN", "NaN", "NaN", "NaN",
"NaN", 1.2]}
df = pd.DataFrame(tbl)
df = df.replace('NaN', np.nan)
df['date'] = pd.to_datetime(df['date'])
def transform(x):
arr = np.empty(x.shape[0])
arr[:] = np.nan
flatten = x.iloc[:, 1:6].values.ravel()
flatten = flatten[~np.isnan(flatten)][:2]
arr[0] = np.diff(flatten)[0]
return pd.DataFrame({"p": arr}, index=x.index)
p = df.groupby("date").apply(transform)
df['p'] = p
df
the resulting dataframe are:
date entry tp1 sl1 tp2 sl2 p
0 2022-02-27 NaN NaN NaN NaN NaN 0.20
1 2022-02-27 NaN NaN NaN NaN NaN NaN
2 2022-02-27 1.2 NaN NaN NaN NaN NaN
3 2022-02-27 NaN 1.4 NaN NaN NaN NaN
4 2022-02-27 NaN NaN NaN 1.5 NaN NaN
5 2022-02-28 NaN NaN NaN NaN NaN -0.15
6 2022-02-28 1.3 NaN NaN NaN NaN NaN
7 2022-02-28 NaN NaN NaN NaN NaN NaN
8 2022-02-28 NaN NaN 1.15NaN NaN NaN
9 2022-02-01 NaN NaN NaN NaN NaN 0.10
10 2022-02-01 1.2 NaN NaN NaN NaN NaN
11 2022-02-01 NaN 1.3 NaN NaN NaN NaN
12 2022-02-01 NaN NaN NaN NaN 1.2 NaN