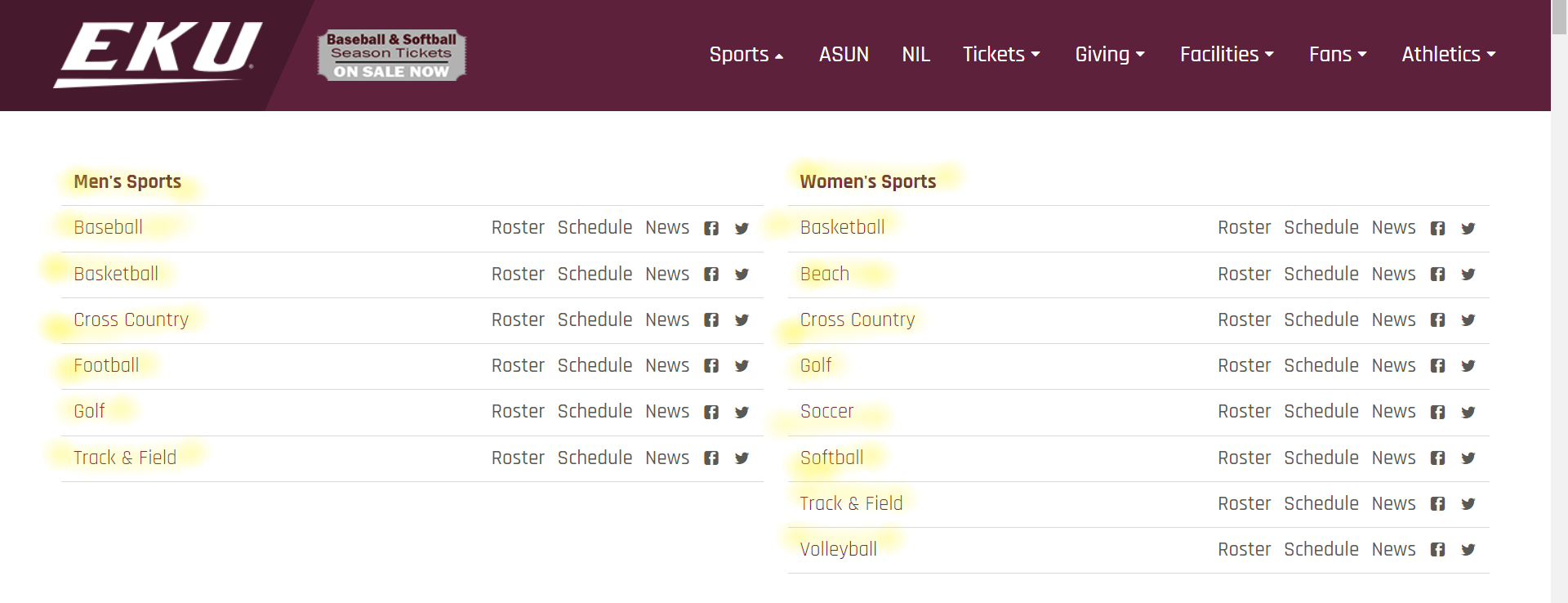
I want to scrape sports menu "text" as highlighted above. https://ekusports.com/
from urllib.request import urlopen
from bs4 import BeautifulSoup
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0"}
url = "https://ekusports.com/"
reqs = requests.get(url, headers=headers)
soup = BeautifulSoup(reqs.text, 'html.parser')
website_text = soup.findAll(text = True)
CodePudding user response:
Use the endpoint to get the menu data.
Here's how:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:97.0) Gecko/20100101 Firefox/97.0",
"X-Requested-With": "XMLHttpRequest",
}
r = requests.get("https://ekusports.com/services/sportnames.ashx", headers=headers).json()
print("\n".join([s["sportInfo"]["sport_title"] for s in r["sports"]]))
Output:
Baseball
Beach Volleyball
Bratzke Center
Cheerleading
Colonel Club
Cross Country
Dance Team
Development
EKUSports Builds
Football
General
Marketing/Promotions
Men's Basketball
Men's Cross Country
Men's Golf
Men's Tennis
Men's Track and Field
Name/Image/Likeness (NIL)
Soccer
Softball
Spirit Groups
Tickets
Track & Field
Volleyball
Women's Basketball
Women's Cross Country
Women's Golf
Women's Tennis
Women's Track and Field
CodePudding user response:
If you are using beautiful soup, it might not be able to get a drop-down menu as they are rendered using JavaScript. You'd need a scraper such as
Selenium
which automates browser and JavaScript renders, with browser window updates on each click, etc. Selenium is also very simple to work with.