I would like to create a pandas datasheet that gets the dictionary a below and adds days_split amount of days from the initial date and creates a table. So for the dictionary below since the first date value is 2/4/2022 1:33:40 PM I would like to add another 10 days into it which would make the range of the first table to be between 2/4/2022 1:33:40 PM and 2/14/2022 1:33:40 PM. Since the last date value in the dictionary is 2/16/2022 9:43:30 AM it will add another days_split amount of days to 2/14/2022 1:33:40 PM so it will create the second tables ranges from 2/14/2022 1:33:40 PM and 2/24/2022 1:33:40 PM. All of the dictionary values could be housed within the 2 tables so there are no more tables that needs to be create. How would I be able to add this function to the code below and achieve the expected Output below?
import pandas as pd
from datetime import timedelta
a = {'Date': {0: '2/4/2022 1:33:40 PM', 1: '2/7/2022 3:09:46 PM', 2: '2/11/2022 9:35:44 AM', 3: '2/14/2022 2:55:33 PM',
4: '2/14/2022 2:57:06 PM', 5: '2/14/2022 2:58:12 PM', 6: '2/16/2022 9:30:44 AM', 7: '2/16/2022 9:32:56 AM', 8: '2/16/2022 9:32:59 AM',
9: '2/16/2022 9:43:30 AM'},
'TransactionType': {0: 'Buy ', 1: 'Buy ', 2: 'Buy ', 3: 'Sell ', 4: 'Sell ',
5: 'Sell ', 6: 'Buy ', 7: 'Buy ', 8: 'Buy ', 9: 'Buy '},
'Symbol': {0: 'META', 1: 'BABA', 2: 'GOOS', 3: 'BABA', 4: 'GOOS', 5: 'META', 6: 'DIS', 7: 'MAR',
8: 'ABNB', 9: 'EXPE'},
'QTY': {0: 185, 1: 21, 2: 75, 3: -21, 4: -75, 5: -185, 6: 10, 7: 9, 8: 10, 9: 9},
'Price': {0: 12.79, 1: 116.16, 2: 28.8, 3: 121.82, 4: 28.06, 5: 12.44, 6: 154.55,
7: 178.75, 8: 179.61, 9: 211.97},
'Amount': {0: -2366.15, 1: -2439.36, 2: -2160.0, 3: 2558.22, 4: 2104.5, 5: 2301.4, 6: -1545.5, 7: -1608.75,
8: -1796.1, 9: -1907.73}}
days_split = 10
df = pd.DataFrame(a)
Expected Output:
Table 1 between 2/4/2022 1:33:40 PM and 2/14/2022 1:33:40 PM
Table 2 between 2/14/2022 1:33:40 PM and 2/24/2022 1:33:40 PM
CodePudding user response:
Use pandas.Grouper
df.Date = pd.to_datetime(df.Date)
df = df.set_index("Date")
groups = df.groupby(pd.Grouper(freq="10D"))
for x in groups:
print(x[1].reset_index())
CodePudding user response:
I would use pd.Grouper, append each dataframe to a list:
l_dfs = []
df['Date'] = pd.to_datetime(df['Date'])
for _, g in df.groupby(pd.Grouper(key='Date',
freq='10D',
offset=df['Date'].min().strftime('%H:%M:%S'))):
l_dfs.append(g)
l_dfs
Ouput:
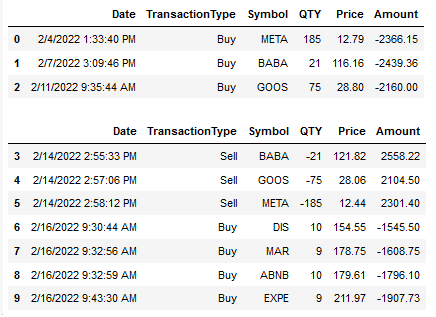
[ Date TransactionType Symbol QTY Price Amount
0 2022-02-04 13:33:40 Buy META 185 12.79 -2366.15
1 2022-02-07 15:09:46 Buy BABA 21 116.16 -2439.36
2 2022-02-11 09:35:44 Buy GOOS 75 28.80 -2160.00,
Date TransactionType Symbol QTY Price Amount
3 2022-02-14 14:55:33 Sell BABA -21 121.82 2558.22
4 2022-02-14 14:57:06 Sell GOOS -75 28.06 2104.50
5 2022-02-14 14:58:12 Sell META -185 12.44 2301.40
6 2022-02-16 09:30:44 Buy DIS 10 154.55 -1545.50
7 2022-02-16 09:32:56 Buy MAR 9 178.75 -1608.75
8 2022-02-16 09:32:59 Buy ABNB 10 179.61 -1796.10
9 2022-02-16 09:43:30 Buy EXPE 9 211.97 -1907.73]