I wanted to showcase a sample example and ask for a solution here. There are a lot of decision tree related queries here, and about choosing ordinal versus categorical data, etc. My example is given as a code below:
from sklearn import tree
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
c1=pd.Series([0,1,2,2,2,0,1,2,0,1,2])
c2=pd.Series([0,1,1,2,0,1,0,0,2,1,1])
c3=pd.Series([0,1,1,2,0,1,1,2,0,2,2])
c4=pd.Series([0,1,2,0,0,2,2,1,2,0,1])# My encoding : Veg:0, Glut:1, None:2
labels=pd.Series([0,0,0,0,1,1,1,0,0,1,1])
dnl=pd.concat([c1,c2,c3,c4],axis=1)
d=dnl.to_numpy()
clf = tree.DecisionTreeClassifier(criterion="entropy",random_state=420,max_depth=2,splitter='best')
clf_tree = clf.fit(d, labels.to_numpy())
print(clf_tree)
score=clf_tree.score(d,labels.to_numpy())
error=1-score
print("The error= ",error)
from sklearn.tree import plot_tree
fig, ax = plt.subplots(figsize=(6, 6)) #figsize value changes the size of plot
plot_tree(clf_tree,ax=ax)
plt.show()
from sklearn.metrics import confusion_matrix
yp=clf_tree.predict(dnl)
print(yp)
print(labels.to_numpy())
cm = confusion_matrix(labels, yp)
print("The confusion matrix= ",cm)
Results:
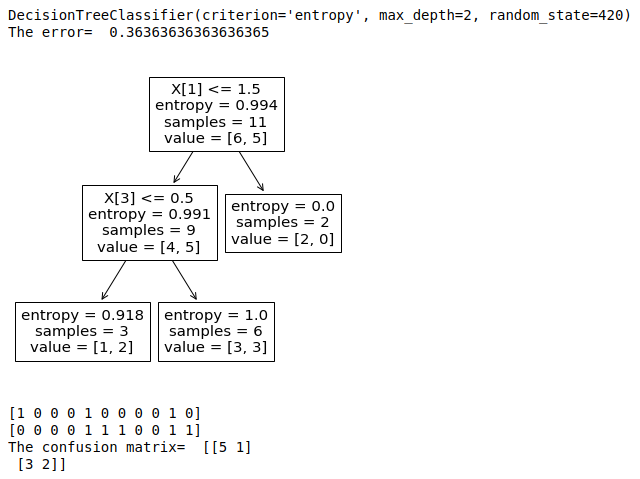
Changing c4 encoding(interchanging 1s and 0s) to below changes the tree! With a lesser misclassification error!
c4=pd.Series([1,0,2,1,1,2,2,0,2,1,0])# Modified encoding: Veg:1, Glut:0,None:2

Why is the decision tree unable to pick mid values as conditions?
CodePudding user response:
I assume the numbers 0,1,2 stand for different categories. Then you should use one-hot encoding before you build the tree. The results will then independent of the label of the category, e.g. '2' will be treated similar as '1'. In your setup '2' will be larger than '1' larger than '0', meaning the categories have an order.
edit:
from sklearn import tree
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import OneHotEncoder
enc= OneHotEncoder(sparse=False)
c1=pd.Series(['0','1','2','2','2','0','1','2','0','1','2'])
c2=pd.Series(['0','1','1','2','0','1','0','0','2','1','1'])
c3=pd.Series(['0','1','1','2','0','1','1','2','0','2','2'])
c4=pd.Series(['0','1','2','0','0','2','2','1','2','0','1'])# My encoding : Veg:0, Glut:1, None:2
labels=pd.Series(['0','0','0','0','1','1','1','0','0','1','1'])
dnl=pd.concat([c1,c2,c3,c4],axis=1)
dnl=dnl.to_numpy()
enc.fit(dnl)
dnl=enc.transform(dnl)
clf = tree.DecisionTreeClassifier(criterion="entropy",random_state=420,max_depth=2,splitter='best')
clf_tree = clf.fit(d, labels.to_numpy())
print(clf_tree)
score=clf_tree.score(d,labels.to_numpy())
error=1-score
print("The error= ",error)
from sklearn.tree import plot_tree
fig, ax = plt.subplots(figsize=(6, 6)) #figsize value changes the size of plot
plot_tree(clf_tree,ax=ax)
plt.show()
from sklearn.metrics import confusion_matrix
yp=clf_tree.predict(dnl)
print(yp)
print(labels.to_numpy())
cm = confusion_matrix(labels, yp)
print("The confusion matrix= \n",cm)