I'm sure that there is a simple way to do this, but I can't seem to find it.
Essentially, I have a DataFrame with a MultiIndex and I want to set one part of a column (corresponding to a value in the first index level) with a Series. However, whatever I try, the values are being set to NaN, even though the index names align.
An example of the things I tried:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(12).reshape(4, 3),
columns=['col1', 'col2', 'col3'],
index=pd.MultiIndex.from_product((('a1', 'a2'), ('b1', 'b2')),
names=['idx1', 'idx2']))
s = pd.Series([100, 101], index=['b1', 'b2'], name='col3')
df.loc['a1', 'col3'] = s
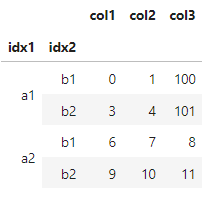
After this, I would expect df to be
col1 col2 col3
idx1 idx2
a1 b1 0 1 100
b2 3 4 101
a2 b1 6 7 8
b2 9 10 11
but it is
col1 col2 col3
idx1 idx2
a1 b1 0 1 NaN
b2 3 4 NaN
a2 b1 6 7 8.0
b2 9 10 11.0
Any idea on how to achieve this without .to_numpy() or .to_list() (since then I would need to check the order of items manually) in a one liner without doing something ridiculous like
df.loc['a1', 'col3'] = s.to_frame().eval('idx1 = "a1"').reset_index().set_index(['idx1', 'idx2'])
CodePudding user response:
Assuming you don't have in s values that are not present in df's Index, you could do:
df.loc[('a1', s.index), 'col3'] = s.values
This will work independently of the order of s
output:
col1 col2 col3
idx1 idx2
a1 b1 0 1 100
b2 3 4 101
a2 b1 6 7 8
b2 9 10 11
CodePudding user response:
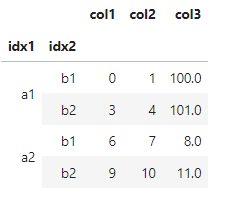
You could use s.to_numpy() or s.tolist():
>>> df.loc['a1', 'col3'] = s.to_numpy()
col1 col2 col3
idx1 idx1
a1 b1 0 1 100.0
b2 3 4 101.0
a2 b1 6 7 8.0
b2 9 10 11.0
CodePudding user response:
Use:
df.loc['a1', 'col3'] = [100, 101]
Output:
Based on your comment:
s = pd.Series([100, 101], index=['b1', 'b2'], name='col3')
s = s.to_list()
df.loc['a1', 'col3'] = s
With the same output.
Based on the other comment!:
s = pd.Series([100, 101], index=(('a1', 'b1'), ('a1', 'b2')), name='col3')
df.loc['a1', 'col3'] = s
Output: