Suppose that you are interested in saving the Economic Calendar table from 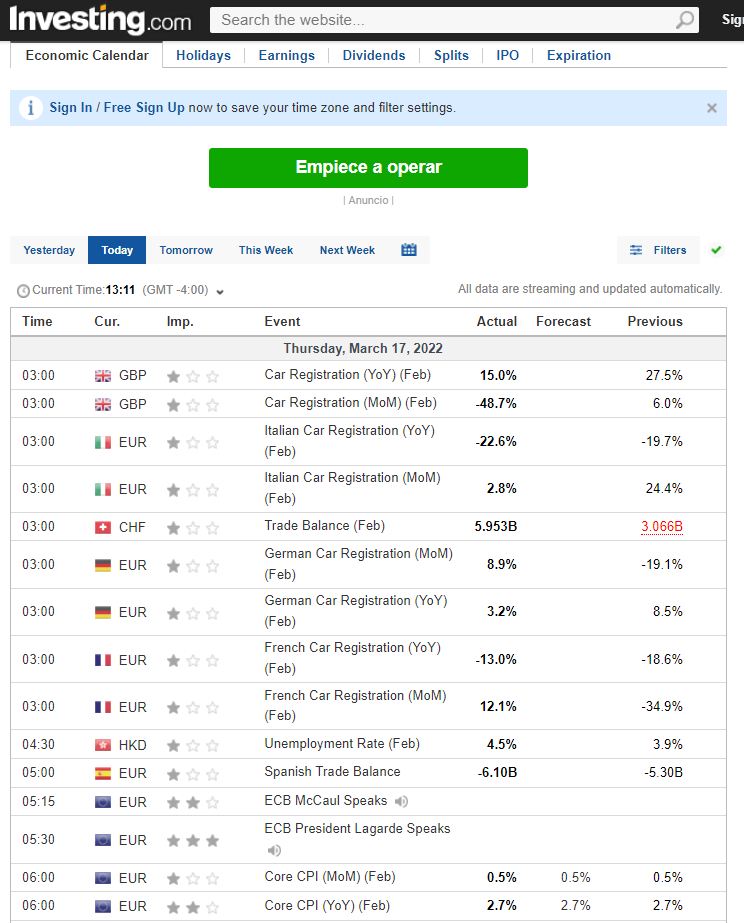
So you write the following code:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import pandas as pd
pd.options.mode.chained_assignment = None # default='warn'
import numpy as np
#the variable that will store the selenium options
opt = Options()
#this allows selenium to take control of your Chrome Browser in DevTools mode.
opt.add_experimental_option("debuggerAddress", "localhost:9222")
#Use the chrome driver located at the corresponding path
s = Service(r'C:\Users\ResetStoreX\AppData\Local\Programs\Python\Python39\Scripts\chromedriver.exe')
#execute the chrome driver with the previous conditions
driver = webdriver.Chrome(service=s, options=opt)
def wait_xpath(code): #function to wait for the element to be located by its XPATH
WebDriverWait(driver, 8).until(EC.presence_of_element_located((By.XPATH, code)))
#go to investing.com to check the economic calendar
driver.get('https://www.investing.com/economic-calendar/')
#wait for the economic calendar table to be located
wait_xpath('/html/body/div[5]/section/div[6]/table')
#wait for the information to load completely
WebDriverWait(driver, 5).until(EC.visibility_of_all_elements_located((By.XPATH, '/html/body/div[5]/section/div[6]/table/tbody/tr')))
#store the table body information
table_body = driver.find_element(By.XPATH, '/html/body/div[5]/section/div[6]/table/tbody')
#store the cells of the table in a list as WebElements
cells = table_body.find_elements(By.TAG_NAME, 'td')
#actual cell list containing the row in string format
cell_list = []
#column names
column_names = ["Time", "Currency", "Volatility expected", "Event", "Actual", "Forecast", "Previous"]
#convert the cells to human readable format and add them to the cell_list
for row in cells[1:]:
cell_list.append(row.text)
#delete the element that appears every 8 elements in the array
cell_list = [word for idx, word in enumerate(cell_list, 1) if idx % 8 != 0]
#reshape the array into an array of unknown arrays and 7 columns
cell_list = np.array(cell_list).reshape(-1, 7).tolist()
#create a dataframe including the column names
df = pd.DataFrame(cell_list, columns=column_names)
#store the volatilities expected (those which are measured with stars)
volatilities_expected = table_body.find_elements(By.XPATH, '/html/body/div[5]/section/div[6]/table/tbody/tr/td[3]')
#actual volatilities list containing the row in string format
volatility_list = []
#convert the volatilities expected to human readable format and add them to the volatility list
for volatility in volatilities_expected:
volatility_list.append(volatility.get_attribute('title'))
#reshape the array into an array of unknown cell and 7 columns
volatility_list = np.array(volatility_list).reshape(-1, 1).tolist()
#add the volatility list to the volatility expected column
df['Volatility expected'] = [v[0] for v in volatility_list]
And after compiling it, you get the following output (for the day of today) :
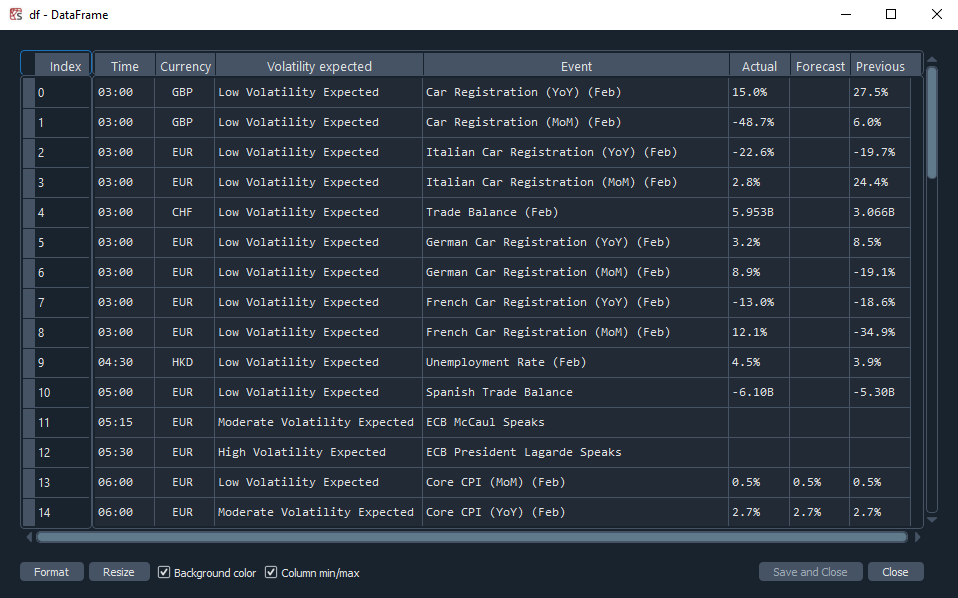
So far, everything seems right, however, when trying the same code as above without the driver.get('https://www.investing.com/economic-calendar/') sentence for the day of tomorrow:
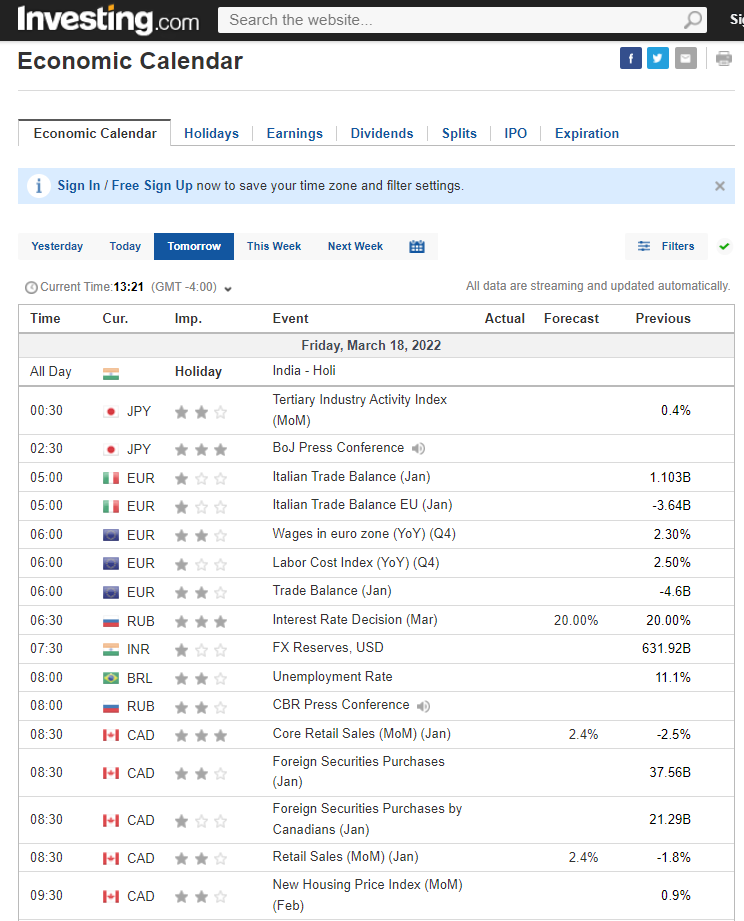
You notice that there's a new row which is just a combination cells informing that tomorrow will be a holiday in India