I have a dataframe like as below
ID,color
1, Yellow
1, Red
1, Green
2, Red
2, np.nan
3, Green
3, Red
3, Green
4, Yellow
4, Red
5, Green
5, np.nan
6, Red
7, Red
8, Green
8, Yellow
fd = pd.read_clipboard(sep=',')
fd = fd.groupby('ID',as_index=False)['color'].aggregate(lambda x: list(x))
As you can see in the input dataframe, some ID's have multiple colors associated to them.
Now, I would like to create a subset of dataframe with ID's that have both Yellow and Green
So, I tried the below and got the list of colors for each ID
fd.groupby('ID',as_index=False)['color'].aggregate(lambda x: list(x))
I would like to check for values like Yellow and Green in the groupby list and then subset the dataframe
I expect my output to be like as shown below (only two IDs have Yellow and Green together)
ID
1
1
8
8
update
input dataframe looks like below
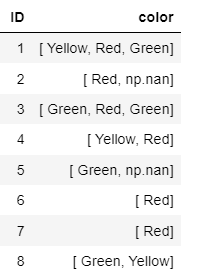
CodePudding user response:
Filter the rows having color as Yellow or Green, then group the dataframe on ID and transform color with nunique to check the ID having 2 unique color.
s = df[df['color'].isin(['Yellow', 'Green'])]
s.loc[s.groupby('ID')['color'].transform('nunique').eq(2), 'ID']
Result
0 1
2 1
14 8
15 8
Name: ID, dtype: int64
Update as per the new requirements, here I'm assuming df1 is the input dataframe obtained after groupby:
s = pd.DataFrame([*df1['color']])
df1[s.mask(~s.isin(['Yellow', 'Green'])).nunique(1).eq(2)]
Result:
ID color
0 1 [Yellow, Red, Green]
7 8 [Green, Yellow]
CodePudding user response:
From your input dataframe, you can use:
colors = ['Yellow', 'Green']
out = df[df['color'].apply(lambda x: set(x).issuperset(colors))]
print(out)
# Output
ID color
0 1 [Yellow, Red, Green]
7 8 [Green, Yellow]