I'm trying to create a string replacer that accepts multilpe replacements.
The ideia is that it would scan the string to find substrings and replace those substrings with another substring.
For example, I should be able to ask it to replace every "foo" for "bar". Doing that is trivial.
The issue starts when I'm trying to add multiple replacements for this function. Because if I ask it to replace "foo" for "bar" and "bar" for "biz", running those replacements in sequence would result in "foo" turning to "biz", and this behavior is unintended.
I tried splitting the string into words and running each replacement function in each word. However that's not bullet proof either because still results in unintended behavior, since you can ask it to replace substrings that are not whole words. Also, I find that very inefficient.
I'm thinking in some way of running each replacer once in the whole string and sort of storing those changes and merging them. However I think I'm overengineering.
Searching on the web gives me trivial results on how to use string.replace with regular expressions, it doesn't solve my problem.
Is this a problem already solved? Is there an algorithm that can be used here for this string manipulation efficiently?
CodePudding user response:
If you modify your string while searching for all occurences of substrings to be replaced, you'll end up modifying incorrect states of the string. An easy way out could be to get a list of all indexes to update first, then iterate over the indexes and make replacements. That way, indexes for "bar" would've been already computed, and won't be affected even if you replace any substring with "bar" later.
Adding a rough Python implementation to give you an idea:
import re
string = "foo bar biz"
replacements = [("foo", "bar"), ("bar", "biz")]
replacement_indexes = []
offset = 0
for item in replacements:
replacement_indexes.append([m.start() for m in re.finditer(item[0], string)])
temp = list(string)
for i in range(len(replacement_indexes)):
old, new, indexes = replacements[i][0], replacements[i][1], replacement_indexes[i]
for index in indexes:
temp[offset index:offset index len(old)] = list(new)
offset = len(new)-len(old)
print(''.join(temp)) # "bar biz biz"
CodePudding user response:
Here's the approach I would take.
I start with my text and the set of replacements:
string text = "alpha foo beta bar delta";
Dictionary<string, string> replacements = new()
{
{ "foo", "bar" },
{ "bar", "biz" },
};
Now I create an array of parts that are either "open" or not. Open parts can have their text replaced.
var parts = new List<(string text, bool open)>
{
(text: text, open: true)
};
Now I run through each replacement and build a new parts list. If the part is open I can do the replacements, if it's closed just add it in untouched. It's this last bit that prevents double mapping of replacements.
Here's the main logic:
foreach (var replacement in replacements)
{
var parts2 = new List<(string text, bool open)>();
foreach (var part in parts)
{
if (part.open)
{
bool skip = true;
foreach (var split in part.text.Split(new[] { replacement.Key }, StringSplitOptions.None))
{
if (skip)
{
skip = false;
}
else
{
parts2.Add((text: replacement.Value, open: false));
}
parts2.Add((text: split, open: true));
}
}
else
{
parts2.Add(part);
}
}
parts = parts2;
}
That produces the following:
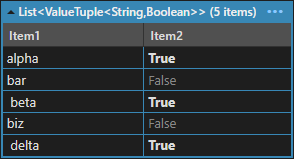
Now it just needs to be joined back up again:
string result = String.Concat(parts.Select(p => p.text));
That gives:
alpha bar beta biz delta
As requested.