I have a backend NodeJS API and I am trying to setting trace id. What I have been thinking is that I would generate a UUID through a Singleton module and then use it across for logging. But since NodeJS is single-threaded, would that mean that UUID will always remain the same for all clients?
For eg: If the API gets a request from https://www.example.com/client-1 and https://www.example-two.com/client-2, would it spin a new process and thereby generate separate UUIDs? or it's just one process that would be running with a single thread? If it's just one process with one thread then I think both the client apps will get the same UUID assigned.
Is this understanding correct?
CodePudding user response:
See this diagram to understand ,how node js server handles requests as compared to other language servers
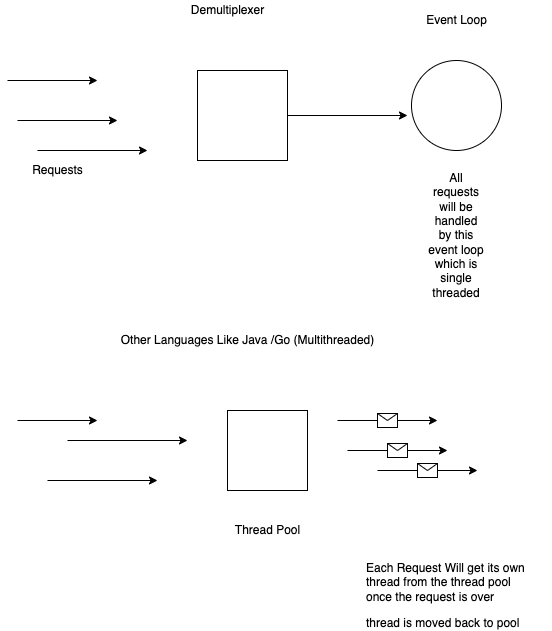
So in your case there won't be a separate thread
And unless you are creating a separate process by using pm2 to run your app or explicitly creating the process using internal modules ,it won't be a separate process
CodePudding user response:
Node.js is a single thread run-time environment provided that internally it does assign threads for requests that block the event loop.
What I have been thinking is that I would generate a UUID through a Singleton module
Yes, it will generate UUID only once and every time you have new request it will reuse the same UUID, this is the main aim of using the Singleton design pattern.
would it spin a new process and thereby generate separate UUIDs? or it's just one process that would be running with a single thread?
The process is the instance of any computer program that can have one or multiple threads in this case it is Node.js(the process), the event loop and execution context or stack are two threads part of this process. Every time the request is received, it will go to the event loop and then be passed to the stack for its execution.
You can create a separate process in Node.js using child modules.
Is this understanding correct?
Yes, your understanding is correct about the UUID Singleton pattern. I would recommend you to see how Node.js processes the request. This video helps you understand how the event loop works.
CodePudding user response:
Nodejs uses only one single thread to run all your Javascript (unless you specifically create a WorkerThread or child_process). Nodejs uses some threads internally for use in some of the library functions, but those aren't used for running your Javascript and are transparent to you.
So, unlike some other environments, each new request runs in the same thread. There is no new process or thread created for an incoming request.
If you use some singleton, it will have the same value for every request.
But since NodeJS is single threaded, would that mean that UUID will always remains the same for all clients?
Yes, the UUID would be the same for all requests.
For eg: If the API gets a request from https://www.example.com/client-1 and https://www.example-two.com/client-2, would it spin a new process and thereby generate separate UUIDs?
No, it would not spin a new process and would not generate a new UUID.
or it's just one process that would be running with a single thread? If it's just one process with one thread then I think both the client apps will get the same UUID assigned.
One process. One thread. Same UUID from a singleton.
If you're trying to put some request-specific UUID in every log statement, then there aren't many options. The usual option is to coin a new UUID for each new request in some middleware and attach it to the req object as a property such as req.uuid and then pass the req object or the uuid itself as a function argument to all code that might want to have access to it.
There is also a technology that has been called "async local storage" that could serve you here. Here's the doc. It can be used kind of like "thread local storage" works in other environments that do use a thread for each new request. It provides some local storage that is tied to an execution context which each incoming request that is still being processed will have, even as it goes through various asynchronous operations and even when it returns control temporarily back to the event loop.
As best I know, the async local storage interface has undergone several different implementations and is still considered experimental.