The dataframe I am talking about
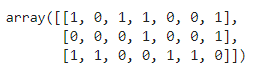
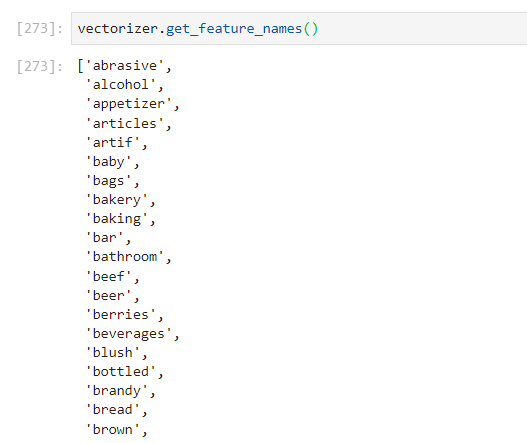
It is bag of items. If we print the following comment, it can be more clear:
vectorizer.get_feature_names()
Output:
['ab', 'ac', 'bv', 'cc', 'dv', 'ff', 'none']
We can see that the 'ab' item is present in the first basket and the second is not, and so on. Based on the data provided, I rewrite the answer:
df = pd.read_csv('GroceriesInitial.csv')
df = df.loc[:, [x for x in df.columns if 'Item' in x]]
corpus = df.apply(lambda x: ' '.join(x.to_numpy().astype(str)), axis=1).values
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df=0, use_idf = False)
X = vectorizer.fit_transform(corpus)
temp = X.toarray()>0
temp.astype(int)
Output:

and corresponding items: