I'm trying to develop a standard dev plot for species but resulting graph for all equal lines doesn't really make much sense. Could someone let me know if this happens because of something I'm doing wrong or just not doing previously?
And I don't get it either why they're reaching 14 when it's 50 for each specie
from sklearn.datasets import load_iris
import pandas as pd
import seaborn as sns
iris = load_iris()
iris_df=pd.DataFrame(iris.data, columns=iris.feature_names)
iris_df['species_id'] = iris.target
iris_df['species_id'] = iris_df['species_id'].replace([0,1,2],iris.target_names)
iris_df['x_pos'] = np.arange(len(iris_df))
print(iris_df)
plt.figure(figsize=(10,5))
ax = sns.barplot(x = "species_id", y = "x_pos", data = iris_df, estimator = np.std)
ax.set_xlabel("Frequency", fontsize = 10)
ax.set_ylabel("Species", fontsize = 10)
ax.set_title("Standard Deviation of Species", fontsize = 15)
CodePudding user response:
you argument y=x_pos is the problem here as the data to evaluate for example for setosa would be [0,1,..., 49, 50] which results in a standard deviation of np.std(range(50)) = 14.43. The same holds for np.std(range(50,100)) = 14.43 and np.std(range(100,150)) = 14.43.
What you want to do is get the standard deviation for each measurement by species. This can be done via
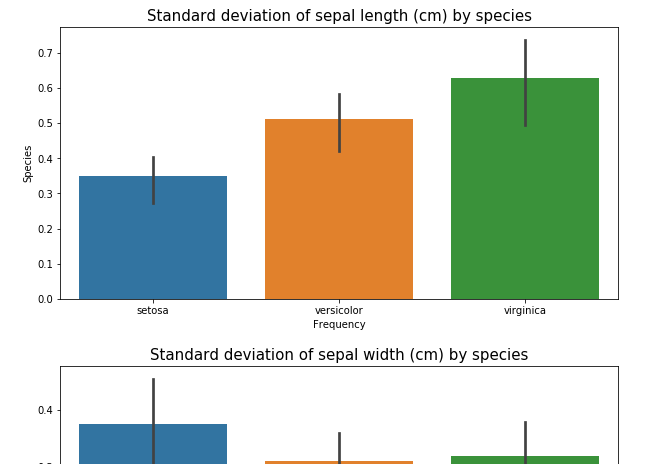
for cat in ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']:
plt.figure(figsize=(10,5))
ax = sns.barplot(x = "species_id", y = cat, data = iris_df, estimator = np.std)
ax.set_xlabel("Frequency", fontsize = 10)
ax.set_ylabel("Species", fontsize = 10)
ax.set_title(f"Standard deviation of {cat} by species", fontsize = 15)
and results in some nice looking plots
Note that seaborn.barplot does not support multiple column names for the parameter y. If you wanted you could rewrite the whole thing using pandas where it would be possible.
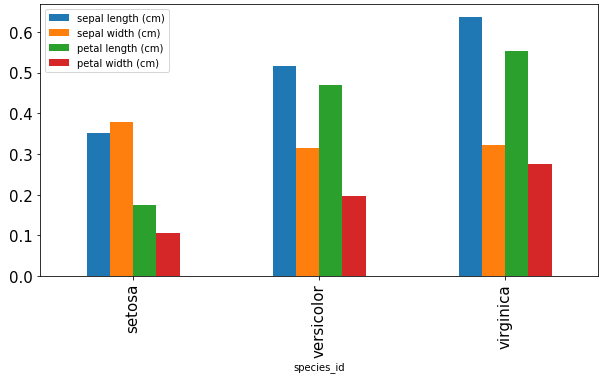
iris_df = iris_df.drop('x_pos',axis=1)
iris_df.groupby('species_id').agg(np.std).plot.bar()
resulting in
CodePudding user response:
x_pos increases by 1 for each row. the dataset is ordered by species, & there are 50 measurements per species, so for each species, you'll get the same standard deviation.
the following plot would help to explain why:
sns.scatterplot(x='x_pos', y=1, hue='species_id', data=iris_df)
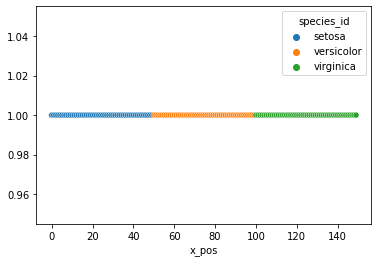
the standard deviation of a series of integers from 0 to 49 is the same as the standard deviation of a series of integers from 50 to 99 and so on.
More interesting plots would be the standard deviation of any feature. example:
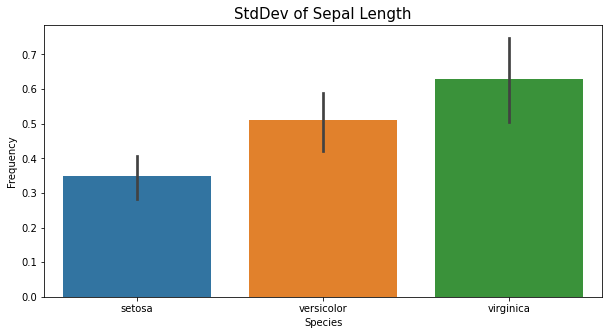
ax = sns.barplot(
x='species_id',
y='sepal length (cm)',
data=iris_df,
estimator=np.std
)
ax.set_xlabel('Frequency', fontsize=10)
ax.set_ylabel('Species', fontsize=10)
ax.set_title('StdDev of Sepal Length', fontsize=15)