I have this code and dataframe
df_initial = pd.DataFrame(data = {'ref':['02','NaN','NaN','NaN','03','NaN','NaN','NaN'], 'Part_ID':['1234-1', 'Shop_Work','repair','scrap','4567-2','Shop_Work','clean','overhaul']})

I wish to somehow 'unstack' rows into columns, to give the following output:
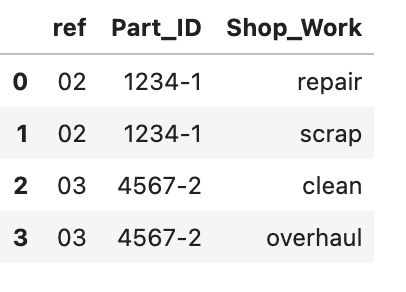
I have tried unstack but this is only for multi-index?
CodePudding user response:
Assuming "Part_ID" and "Shop_Work" are fixed:
# ensure real NaNs
df_initial = df_initial.replace('NaN', float('nan'))
# compute a mask
m = df_initial['ref'].isna()
df_out = (df_initial[~m] # remove NaN rows
.merge(df_initial # merge with NaN rows
.ffill()[m&m.shift()] # except first NaN row
.rename(columns={'Part_ID': 'Shop_Work'}), # rename column
on='ref')
)
output:
ref Part_ID Shop_Work
0 02 1234-1 repair
1 02 1234-1 scrap
2 03 4567-2 clean
3 03 4567-2 overhaul
Alternatively, with two masks, in case the "Shop_Work" rows are not always first or even there:
# mask for NaN
m1 = df_initial['ref'].isna()
# mask for Shop_Work rows
m2 = df_initial['Part_ID'].ne('Shop_Work')
df_out = (df_initial[~m]
.merge(df_initial
.ffill()[m1&m2]
.rename(columns={'Part_ID': 'Shop_Work'}),
on='ref')
)
CodePudding user response:
Use:
#if NaNs are string replace to missing values
df_initial['ref'] = df_initial['ref'].replace('NaN', np.nan)
#test missing values
m = df_initial['ref'].isna()
#forward filling missing values
df_initial['ref'] = df_initial['ref'].ffill()
#new column Shop_Work
df_initial['Shop_Work'] = df_initial['Part_ID']
#replace Part_ID by mask to NaN and forward filling
df_initial['Part_ID'] = df_initial['Part_ID'].mask(m).ffill()
#get out Shop_Work rows
df = df_initial[df_initial['Shop_Work'].ne('Shop_Work') & m].reset_index(drop=True)
print (df)
ref Part_ID Shop_Work
0 02 1234-1 repair
1 02 1234-1 scrap
2 03 4567-2 clean
3 03 4567-2 overhaul