Does anyone know a numpy alternative to pd.factorize()?
I have a need for speed in an algorithm, and would like to not use the pandas dataframe.
So for instance,
test = np.array(['yo', 'whats', 'up', 'whats', 'up', 'yo'])
shall return
pd.factorize(pd.Series(test))
array([0, 1, 2, 1, 2, 0])
CodePudding user response:
You can use 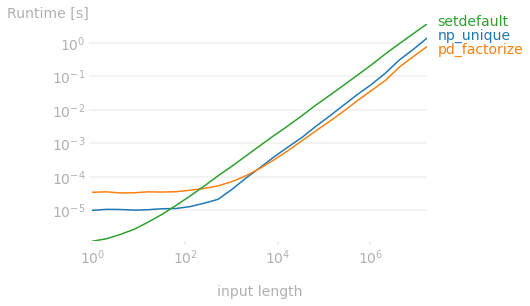
comparison on 1 to ~33M rows, with 52 factors
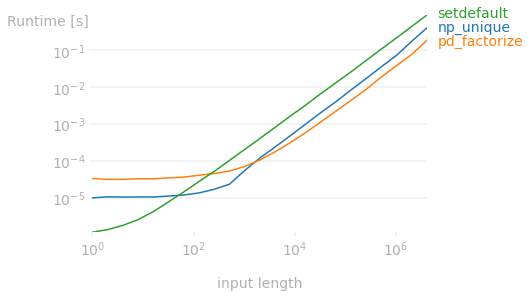
CodePudding user response:
Already a great answer above. Wall time for Option # 2 below was almost half:
import numpy as np
test = np.array(['yo', 'whats', 'up', 'whats', 'up', 'yo'])
Option # 1:
%%time
x, y = np.unique(test, return_inverse=True)
y
Output:
CPU times: user 103 µs, sys: 23 µs, total: 126 µs
Wall time: 110 µs
array([2, 1, 0, 1, 0, 2])
Option # 2:
d={}
[d.setdefault(w, i) for i, w in enumerate(test)]
Output:
CPU times: user 60 µs, sys: 1e 03 ns, total: 61 µs
Wall time: 64.1 µs
[0, 1, 2, 1, 2, 0]