I have the following dataframe:
| ID | Fruit | Price | Location | Start_Date | End_Date |
|---|---|---|---|---|---|
| 01 | Orange | 12 | ABC | 01-03-2015 | 01-05-2015 |
| 01 | Orange | 9.5 | ABC | 01-03-2015 | 01-05-2015 |
| 02 | Apple | 10 | PQR | 04-09-2019 | 04-11-2019 |
| 06 | Orange | 11 | ABC | 01-04-2015 | 01-06-2015 |
| 05 | Peach | 15 | XYZ | 07-11-2021 | 07-13-2021 |
| 08 | Apple | 10.5 | PQR | 04-09-2019 | 04-11-2019 |
| 10 | Apple | 10 | LMN | 04-10-2019 | 04-12-2019 |
| 03 | Peach | 14.5 | XYZ | 07-11-2020 | 07-13-2020 |
| 11 | Peach | 12.5 | ABC | 01-04-2015 | 01-05-2015 |
| 12 | Peach | 12.5 | ABC | 01-03-2015 | 01-05-2015 |
I want to form a group of IDs that belong to the same location, fruit, and range of start date and end date. The date interval condition is that we only group those ids together whose start_date and end_date are no more than 3 days apart. Eg. ID 06 start_date is 01-04-2015 and end_date is 01-06-2015. ID 01 start_date is 01-03-2015 and end_date is 01-05-2015. So ID 06 and 01's start_date and end_date are only 1 day apart so the merge is acceptable (i.e. these two ids can be grouped together if other variables like location and fruit match).
Also, I only want to output groups with more than 1 unique IDs.
My output should be (the start date and end date is merged):
| ID | Fruit | Price | Location | Start_Date | End_Date |
|---|---|---|---|---|---|
| 01 | Orange | 12 | ABC | 01-03-2015 | 01-06-2015 |
| 01 | Orange | 9.5 | |||
| 06 | Orange | 11 | |||
| 11 | Peach | 12.5 | |||
| 12 | Peach | 12.5 | |||
| 02 | Apple | 10 | PQR | 04-09-2019 | 04-11-2019 |
| 08 | Apple | 10.5 |
IDs 05,03 get filtered out because it's a single record (they dont meet the date interval condition). ID 10 gets filtered out because it's from a different location.
I have no idea how to merge intervals for 2 such date columns. I have tried a few techniques to test out grouping (without the date merge).
My latest one is using grouper.
output = df.groupby([pd.Grouper(key='Start_Date', freq='D'),pd.Grouper(key='End_Date', freq='D'),pd.Grouper(key='Location'),pd.Grouper(key='Fruit'),'ID']).agg(unique_emp=('ID', 'nunique'))
Need help getting the output. Thank you!!
CodePudding user response:
Here is a slow/non-vectorized approach where we "manually" walk through sorted date values and assign them to bins, incrementing to the next bin when the gap is too large. Uses a function to add new columns to the df. Edited so that the ID column is the index
from datetime import timedelta
import pandas as pd
#Setup
df = pd.DataFrame(
columns = ['ID', 'Fruit', 'Price', 'Location', 'Start_Date', 'End_Date'],
data = [
[1, 'Orange', 12.0, 'ABC', '01-03-2015', '01-05-2015'],
[1, 'Orange', 9.5, 'ABC', '01-03-2015', '01-05-2015'],
[2, 'Apple', 10.0, 'PQR', '04-09-2019', '04-11-2019'],
[6, 'Orange', 11.0, 'ABC', '01-04-2015', '01-06-2015'],
[5, 'Peach', 15.0, 'XYZ', '07-11-2021', '07-13-2021'],
[8, 'Apple', 10.5, 'PQR', '04-09-2019', '04-11-2019'],
[10, 'Apple', 10.0, 'LMN', '04-10-2019', '04-12-2019'],
[3, 'Peach', 14.5, 'XYZ', '07-11-2020', '07-13-2020'],
[11, 'Peach', 12.5, 'ABC', '01-04-2015', '01-05-2015'],
[12, 'Peach', 12.5, 'ABC', '01-03-2015', '01-05-2015'],
]
)
df['Start_Date'] = pd.to_datetime(df['Start_Date'])
df['End_Date'] = pd.to_datetime(df['End_Date'])
df = df.set_index('ID')
#Function to bin the dates
def create_date_bin_series(dates, max_span=timedelta(days=3)):
orig_order = zip(dates,range(len(dates)))
sorted_order = sorted(orig_order)
curr_bin = 1
curr_date = min(dates)
date_bins = []
for date,i in sorted_order:
if date-curr_date > max_span:
curr_bin = 1
curr_date = date
date_bins.append((curr_bin,i))
#sort the date_bins to match the original order
date_bins = [v for v,_ in sorted(date_bins, key = lambda x: x[1])]
return date_bins
#Apply function to group each date into a bin with other dates within 3 days of it
start_bins = create_date_bin_series(df['Start_Date'])
end_bins = create_date_bin_series(df['End_Date'])
#Group by new columns
df['fruit_group'] = df.groupby(['Fruit','Location',start_bins,end_bins]).ngroup()
#Print the table sorted by these new groups
print(df.sort_values('fruit_group'))
#you can use the new fruit_group column to filter and agg etc
Output
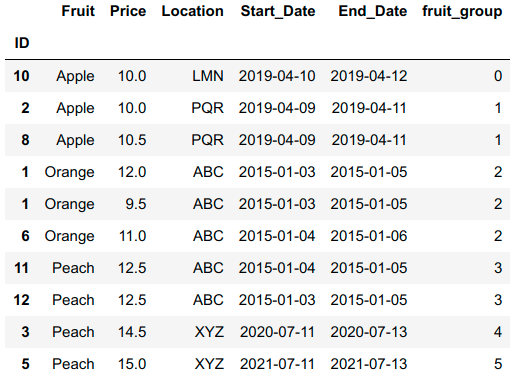
CodePudding user response:
This is essentially a gap-and-island problem. If you sort your dataframe by Fruit, Location and Start Date, you can create islands (i.e. fruit group) as follow:
- If the current row's Fruit or Location is not the same as the previous row's, start a new island
- If the current row's End Date is more than 3 days after the island's Start Date, make a new island
The code:
for col in ["Start_Date", "End_Date"]:
df[col] = pd.to_datetime(df[col])
# This algorithm requires a sorted dataframe
df = df.sort_values(["Fruit", "Location", "Start_Date"])
# Assign each row to an island
i = 0
islands = []
last_fruit, last_location, last_start = None, None, df["Start_Date"].iloc[0]
for _, (fruit, location, start, end) in df[["Fruit", "Location", "Start_Date", "End_Date"]].iterrows():
if (fruit != last_fruit) or (location != last_location) or (end - last_start > pd.Timedelta(days=3)):
i = 1
last_fruit, last_location, last_start = fruit, location, start
else:
last_fruit, last_location = fruit, location
islands.append(i)
df["Island"] = islands
# Filter for islands having more than 1 rows
idx = pd.Series(islands).value_counts().loc[lambda c: c > 1].index
df[df["Island"].isin(idx)]