I have uploaded my dataset into Jupyter, it has 531 columns and 116 rows. So far I have replaced NaN values with 0 and now i am stucked with last step. I would like to replicate first columns values into other columns, based on condition that rows values will be bigger than 0.
I identified 3 parts to this task:
- iterate over whole set ( ex. list comprehension, for i in df)
- check whether values are bigger than 0 ( if i>0
- assign values from column0 to each field>0
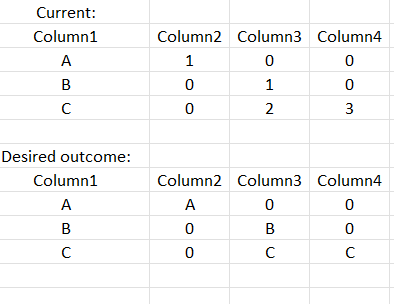
I have tried list comprehension and googled how to duplicate values from Column0 based on the condition, but i am having difficulty understanding how can I replace them dynamically, ex. without fixed value. Additionally, i am wondering how should i define values to be inserted. How i started:
for i in df:
if i>0:
i...
I was considering using the where clause, but cannot get a hint how should i ask python to iterate over all table without defining which colums to replace specifically.
df = np.where(df == 0, df['replace all columns '], df[:1])
df[:,0] goes for replacing values with those from column0
Could you please suggest me any hints/ action points?
CodePudding user response:
Using a simple for loop. For example:
for col in df:
df[col] = np.where(df[col]!=0, df['Column1'], df[col])