I have a pandas dataframe that looks like below
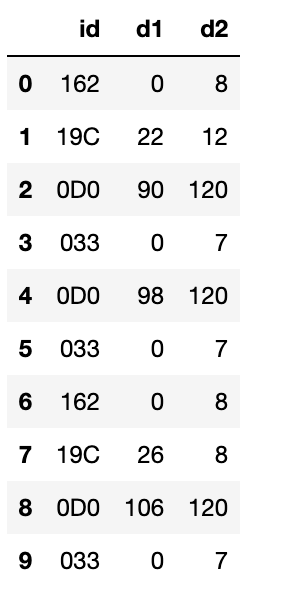
I would like to construct the DataFrame as follows. I want to merge values of id columns with column headers and create a new dataframe like below. The number of rows is the same as in the original table. For every id, new columns should be created as id_d1 and id_d2. Then values should be updated based on id and column value. Values should be changed if the id values are changing and other raw values should be the same as the previous raw.
This is just an example of the dataframe. In the original dataframe I have 106 unique values in id column and 8 column values (d1, d2,...d8). Hence creating column headings manually is also not practical (there will be 106*8 = 848 columns). I'm trying to find an efficient way to do that as I have a large dataset (over 100000 rows)
Any suggestion on what is the best way to do this is highly appreciated
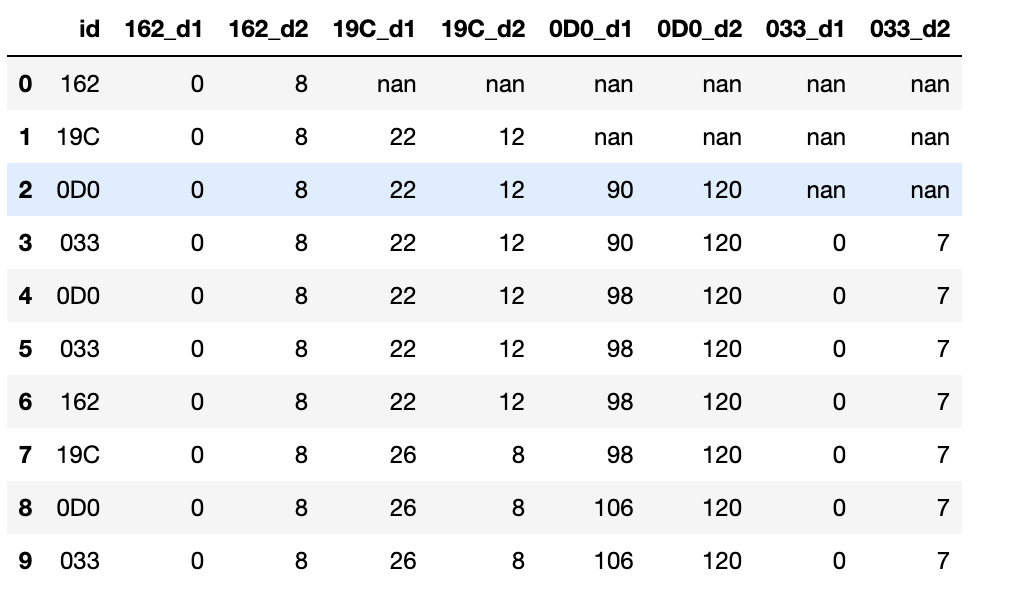
CodePudding user response:
This should do it:
import pandas as pd
import numpy as np
df = pd.DataFrame(data={"id": ['162', '19C', '0D0', '033', '0D0',
'033', '162', '19C', '0D0', '033'],
"d1": [0, 22, 90, 0, 98,
0, 0, 26, 106, 0],
"d2": [8, 12, 120, 7, 120,
7, 8, 8, 120, 7]})
# loop through unique "id" values
for x in df["id"].unique():
# loop through select columns
for p in list(df.columns[1:3]):
# create new column, only use matched id value data, and forward fill the rest
df[x "_" p] = df[p].where(df["id"] == x, np.nan).ffill()
As you have up to d8 in your actual dataframe, you would need to change the nested for loop to accommodate. It may be easier to just create a list, i.e. cols = ["d1", "d2", ...] and use that instead.