Hello, I am working on the resolution of a problem that has to do with time series.
I am plotting y = sin (x) with 10000 values
Then, to each value (y), I associate an index calculated based on the next values (between 0 and 1)
- if the next 150 values are lower than the current one, then this index will be set to 1
- If the next 150 values are higher then the current one, then this index will be set to 0
Then I'm trying to set up a LSTM network using tensorflow/keras in order to predict this index based on the last 150 values, which should be pretty trivial for a sinus function.
Here is the code and the explanation :
- I make an array with 10000 values of sin(x)
import numpy as np
import math
from matplotlib import pyplot as plt
n = 10000
array = np.array([math.sin(i*0.02) for i in range(1, n)])
fig, ax = plt.subplots()
ax.plot([(i*0.02) for i in range(1, n)], array, linewidth=0.75)
plt.show()
- Calculate the associated index, here SELL_INDEX
SELL_INDEX = np.zeros((len(array), 1))
for index, row in enumerate(array):
if index > len(array) - 150:
continue
max_price = np.amax(array[index:index 150])
min_price = np.amin(array[index:index 150])
current_sell_index = (row - min_price) / (max_price - min_price)
SELL_INDEX[index][0] = current_sell_index
data_with_sell_index = np.hstack((array.reshape(-1,1), SELL_INDEX))
data_final = np.hstack( (data_with_sell_index, np.arange(len(data_with_sell_index)).reshape(-1, 1)) )
fig, ax = plt.subplots()
ax.scatter(data_final[:,2], data_final[:,0] , c = data_final[:,1], s = .5)
plt.show()
Here is the plot (sin(x), SELL_INDEX : 1 being yellow, 0 being purple )
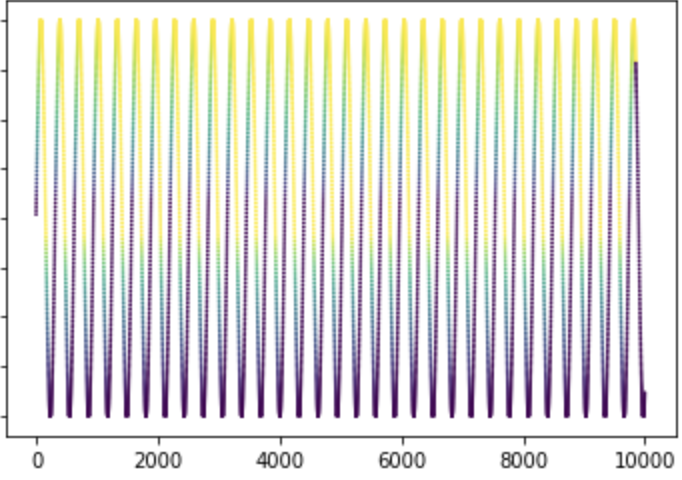
- Here is the creation of the model
import tensorflow as tf
from sklearn.preprocessing import MinMaxScaler
from tensorflow.python.keras import models, Input, Model
from tensorflow.python.keras.layers import LSTM, Dense, Dropout
# from neural_intelligence.batches_generator import generate_smart_lstm_batch, get_smart_lstm_data
class LearningRateReducerCb(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
old_lr = self.model.optimizer.lr.read_value()
new_lr = old_lr * 0.99
print("\nEpoch: {}. Reducing Learning Rate from {} to {}".format(epoch, old_lr, new_lr))
self.model.optimizer.lr.assign(new_lr)
# Model creation
input_layer = Input(shape=(150, 1))
layer_1_lstm = LSTM(100, return_sequences=True)(input_layer)
dropout_1 = Dropout(0.0)(layer_1_lstm)
layer_2_lstm = LSTM(200, return_sequences=True)(dropout_1)
dropout_2 = Dropout(0.0)(layer_2_lstm)
layer_3_lstm = LSTM(100)(dropout_2)
output_sell_index_proba = Dense(1, activation='sigmoid')(layer_3_lstm)
model = Model(inputs=input_layer, outputs=output_sell_index_proba)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
- Training the model
def generate_batch(dataset_x, dataset_y, sequence_length):
x_data, y_data = [], []
for i in range(len(list(zip(dataset_x, dataset_y))) - sequence_length - 1):
x_data.append(dataset_x[i:i sequence_length])
y_data.append(dataset_y[i sequence_length])
return np.array(x_data), np.array(y_data)
x, y = generate_batch(data_final[:,0], data_final[:,1], sequence_length=150)
x = x.reshape(x.shape[0], x.shape[1], 1)
y = y.reshape(x.shape[0], 1, 1)
print(x.shape, y.shape)
model.fit(x, y, callbacks=[LearningRateReducerCb()], epochs=2,
validation_split=0.1, batch_size=64, verbose=1)
Here is my issue, the accuracy never goes above 0.52, I don't understand why, everything seems to be ok to me.
This should be very simple for such a powerful tool as LSTM, but it can figure out what the index could be.
If you could me help in any way, you're welcome, thank you
EDIT : To plot the result, use
data = np.array(data_final[:,0])
results = np.array([])
for i in range (150, 1000):
result = model.predict(data[i - 150 : i].reshape(1, 150, 1))
results = np.append(result, results)
data = data[150:1000]
fig, ax = plt.subplots()
ax.scatter([range(len(data))], data.flatten() , c = results.flatten(), s= 1)
plt.show()
It seems to be working, the issue is : why is the accuracy never goes up while training ?
This leads me to investigate on what was the problem instead of trying predicting
CodePudding user response:
This may be simplistic, but to my mind you are only accurately predicting half your curve.
- This is where the blue and yellow lines overlap in your fit chart. The accuracy measure will be computed over all of the rows unless you tell it otherwise.
- This intuitively explains why your accuracy is c. 50%. You should be able to confirm this by splitting your data into these two portions and calculating the accuracy on each
I suggest playing around with your features and transformations to understand which type of shapes predict your sine curve with a higher accuracy (and give a fuller overlap between the lines).