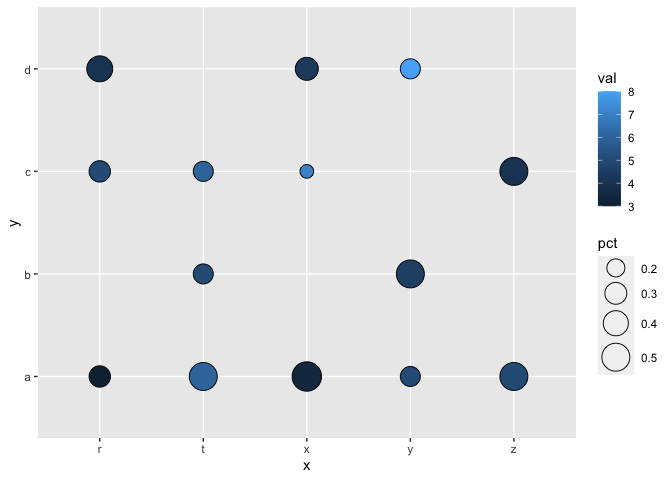
I am trying to produce a plot with a discrete variable on x axis and another discrete variable on y axis, with points that are colored by the mean of val and sized by the proportion of cases in x.
The data looks like this:
df1 <- data.frame(y=c("a","b","c","a","d","a","a","c","d","a","b","c","a","d","a","a","c","d","d","a","b","c","a","d","a","a","c","d"),
x=c("x","y","z","t","r","x","x","x","y","z","t","r","r","x","y","z","t","r","x","x","y","z","t","r","r","x","r","x"),
val=c(1,4,1,6,3,6,2,7,8,2,5,7,2,8,5,8,6,4,2,4,5,7,6,5,4,4,3,3))
I have tried with geom_count and with the following:
ggplot(data = df1, aes(x=x, y=y, fill=val))
stat_sum(aes(size=..prop.., group=x))
scale_size_area(max_size = 10)
{kind=link}
But there must be some weird overrides I am unaware of. The props produced in the size parameter are not correct, as if I remove fill variable from the plot they are different. Can anyone help me? I have scrutinized google but I have not find any solutions.
CodePudding user response:
One option would be to compute the counts, percentages and the mean for the fill value outside of ggplot and using geom_point to plot the aggregated data:
library(ggplot2)
library(dplyr)
df2 <- df1 |>
group_by(x, y) |>
summarise(n = n(), val = mean(val)) |>
mutate(pct = n / sum(n)) |>
ungroup()
#> `summarise()` has grouped output by 'x'. You can override using the `.groups`
#> argument.
ggplot(df2, aes(x, y, size = pct, fill = val))
geom_point(shape = 21)
scale_size_area(max_size = 10)