I have average annual spatial temperature data for the last 15 years, and I am interested in finding the change in temperature in that time period. Basically, the purpose is to see whether the temperature has increased or not (indicating global warming/climate change) over this time, and if it has increased then by how many degrees? Then I will be able to say, for example, the temperature increased in this time period by X degrees Celsius.
How can I do this in R?
Sample data
year = c(2005, 2005, 2005, 2005, 2006, 2006, 2006, 2006, 2007, 2007, 2007, 2007, 2008, 2008, 2008, 2008)
Tmean = c(24, 24.5, 25.8,25, 24.8, 25, 23.5, 23.8, 24.8, 25, 25.2, 25.8, 25.3, 25.6, 25.2, 25)
Code
library(tidyverse)
df = data.frame(year, Tmean)
# Find the change/increase/decrease in temperature in the time period
# Stuck on method.....
CodePudding user response:
First of all, you can plot your data along with a regression line to see whether it looks as though the temperature is indeed increasing:
ggplot(df, aes(year, Tmean))
geom_point(colour = 'deepskyblue4', size = 3)
geom_smooth(method = lm, linetype = 2, color = 'red4', se = FALSE)
theme_light()
theme(text = element_text(size = 16))
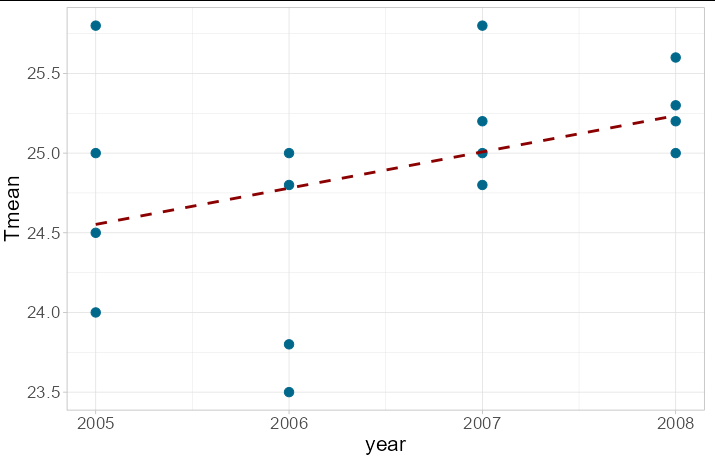
And it does seem to have increased by about 0.75 degrees between the first and last years of this data set. To quantify this, we can run a linear regression model:
model <- lm(Tmean ~ year, data = df)
summary(model)
#>
#> Call:
#> lm(formula = Tmean ~ year, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.28000 -0.21437 0.00625 0.25625 1.24750
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) -431.5850 284.1228 -1.519 0.151
#> year 0.2275 0.1416 1.607 0.130
#>
#> Residual standard error: 0.6333 on 14 degrees of freedom
#> Multiple R-squared: 0.1557, Adjusted R-squared: 0.09536
#> F-statistic: 2.581 on 1 and 14 DF, p-value: 0.1304
The interpretation here is that temperature increased by an average of 0.2275 degrees per year, or 3 * 0.2275, which is 0.6825 degrees. The p value of 0.130 tells us that this change was not statistically significant (i.e. it could have been due to chance)
CodePudding user response:
Is this what you are looking for?
year = c(2005, 2005, 2005, 2005, 2006, 2006, 2006, 2006, 2007, 2007, 2007, 2007, 2008, 2008, 2008, 2008)
Tmean = c(24, 24.5, 25.8,25, 24.8, 25, 23.5, 23.8, 24.8, 25, 25.2, 25.8, 25.3, 25.6, 25.2, 25)
data = data.frame(year, Tmean)
data = data %>% group_by(year) %>% mutate(min = min(Tmean), max = max(Tmean)) %>%
mutate(diff = max - min)
data = data %>% select(-c(Tmean, min, max)) %>% unique()
print(data)