In my data set, I have students data with some attempts - First,Second,Third,Four and Five, I have to find out each students for how many they taken attempt for taking >=50 marks, If one person complete in first attempt, then my output showing - "Column title" and sum of marks.
Here is my dummy data set
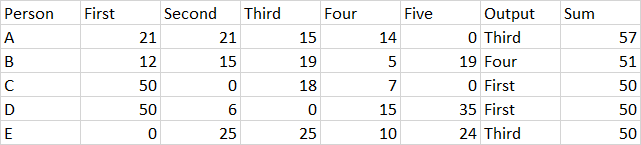
Person First Second Third Four Five
0 A 21 21 15 14 0
1 B 12 15 19 5 19
2 C 50 0 18 7 0
3 D 50 6 0 15 35
4 E 0 25 25 10 24
Output:
I am trying to find out but I am stuck in getting the correct solution.
Here is my work
import pandas as pd
import numpy as np
df
df['Total'] = df.sum(axis=1)
df['Output'] = df.apply(lambda row: (row['First'] row['Second'] row['Third']) row['Four'] row['Five'] if row['A'] > 50)
Output = np.array(df[['First','Second','Third','Four','Five']].values.tolist())
df[['First','Second','Third','Four','Five']] = np.where(Output > 50, 50, Output).tolist()
df.groupby('Person')[['First','Second','Third','Four','Five']>50].sum()
df['Output'] = np.where(df.sum(axis=1)) >50
Please help.
CodePudding user response:
Try this:
cmax = df.select_dtypes(include="number").cumsum(axis=1)
df['Output'] = cmax.ge(50).idxmax(axis=1)
df['Sum'] = cmax.stack().loc[zip(df.index, df['Output'])].to_numpy()
df
Output:
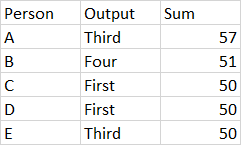
Person First Second Third Four Five Output Sum
0 A 21 21 15 14 0 Third 57
1 B 12 15 19 5 19 Four 51
2 C 50 0 18 7 0 First 50
3 D 50 6 0 15 35 First 50
4 E 0 25 25 10 24 Third 50
Details:
Let's use select_dtypes to only get those attempts columns with numbers, then do a cumulative sum of the rows with axis=1.
Then, use that dataframe and find all values equal or greater than 50 to create a boolean dataframe. Using idxmax along the row, we can find the first True value, ie the first time the cumulative sum reaches 50. And, idxmax will return that column headers.
Lastly, we can use stack the cumulative sum dataframe and use loc to get values from cumulative sum that matches, the index with the output column.
CodePudding user response:
Try this:
df = pd.DataFrame([['A',21,21,15,14,0],['B',12,15,19,5,19],['C',50,0,18,7,0],['D',50,6,0,15,35],['E',0,25,25,10,14]])
df.columns= 'Person,First,Second,Third,Four,Five'.split(',')
data = []
for row in df.iloc:
total = 0
index = 1
for value in row.values[1:]:
total = value
if total >= 50:
break
index = 1
data.append({'Output': row.keys()[index], 'Sum': total})
df = pd.concat([df.iloc[:, 0],pd.DataFrame(data)],axis=1)
Output:
Person Output Sum
0 A Third 57
1 B Four 51
2 C First 50
3 D First 50
4 E Third 50
In [2]: import pandas as pd
In [3]: df = pd.DataFrame([['A',21,21,15,14,0],['B',12,15,19,5,19],['C',50,0,18,7,0],['D',50,6,0,15,35],['E',0,25,25,10,14]])^M
...: df.columns= 'Person,First,Second,Third,Four,Five'.split(',')^M
...: data = []^M
...: for row in df.iloc:^M
...: total = 0^M
...: index = 1^M
...: for value in row.values[1:]:^M
...: total = value^M
...: if total >= 50:^M
...: break^M
...: index = 1^M
...: data.append({'Output': row.keys()[index], 'Sum': total})^M
...: ^M
...: df = pd.concat([df.iloc[:, 0],pd.DataFrame(data)],axis=1)
In [4]: df
Out[4]:
Person Output Sum
0 A Third 57
1 B Four 51
2 C First 50
3 D First 50
4 E Third 50
CodePudding user response:
I think you can do something like this:
columns = ['First','Second','Third','Four','Five']
THRESHOLD = 50
def f(x):
sum= 0
x['Output'] = ''
x['Sum']=0
for column in columns:
sum =x[column]
if (sum>=THRESHOLD):
x['Output'] = column
x['Sum'] = sum
break
return x
df.apply(f, axis = 1)