I would like to learn how to specify a "subset-sum" in a dataframe
My dataframe looks like this:
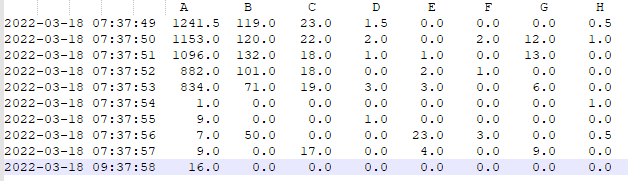
The Data/Time column is the dataframes' index
With
Sum = data['A'].sum()
I get the total sum of column A.
My aim is to sum up a subset of rows only like between 2022-03-18 07:37:51 and 2022-03-18 07:37:55
so that I get a "sum" row:
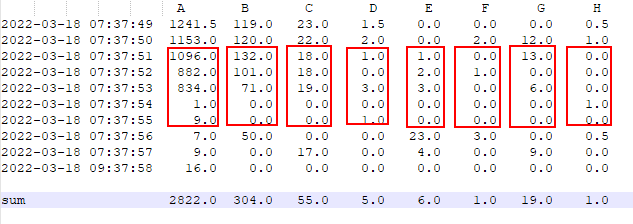
How can I specify the row numbers to be summed for each column, especially when the index is in datetime format?
CodePudding user response:
data[(data.index >= '2020-01-01 00:00:16') & (data.index <= '2020-01-01 00:00:17')].sum(axis=0)
simply, use axis = 0 for each coulmn sum, and check by a.index >= '2020-01-01 00:00:16' and equivalent for upper bound
if you want to use datetime module:
from datetime import datetime
data[(data.index >= datetime(2020, 1, 1, 0, 0, 16)) & (data.index <= datetime(2020, 1, 1, 0, 0, 17))].sum(axis=0)
CodePudding user response:
If you need a more generic criterion to select rows, not only time ranges then you could work with this:
df = pd.DataFrame([[12,5,7], [13,7,4], [14,7,23], [15,71,9], [16,5,4], [17,55,42]], columns=['T', 'A', 'B'])
print(df)
T A B
0 12 5 7
1 13 7 4
2 14 7 23
3 15 71 9
4 16 5 4
5 17 55 42
range_idx = df['T'].between(13,15) # or another selection
df[range_idx]
T A B
1 13 7 4
2 14 7 23
3 15 71 9
df[range_idx][['A','B']].sum()
Out[42]:
A 85
B 36