I want to divide the line into a date, description, and amount. The last digits are the amount that can contain Cr. I have a line like the following:
Date Description Amount
13/03/2021 XYZ ABC 428.00 31,408.37 Cr
17/03/2021 ZOOM.US 111-222-333 WWW.ZOOM.U USD 5.29 841.18
The regex that I used is:
regex_filter = re.compile(r'(\d{2}/\d{2}/\d{4}) (.*?) ([\d,] \.\d{2}) ')**
And what I got is:
Date - 13/03/2021
Description - XYZ ABC
Amount - 428.00
I want the amount to be 31,408.37 Cr and for the second one amount should be 841.18. So I want digits and characters up to a space reading from the end.
How can I get this?
CodePudding user response:
You may use this regex with anchors and optional group:
^(\d{2}/\d{2}/\d{4})\s (.*?)\s ((?:\d (?:,\d )*\.\d{2})(?: Cr)?)$
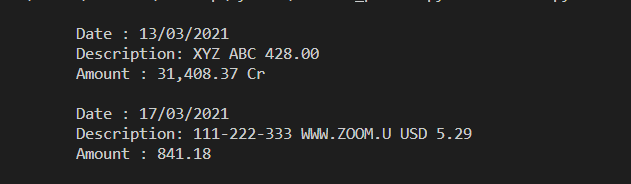
See the following parsed data:
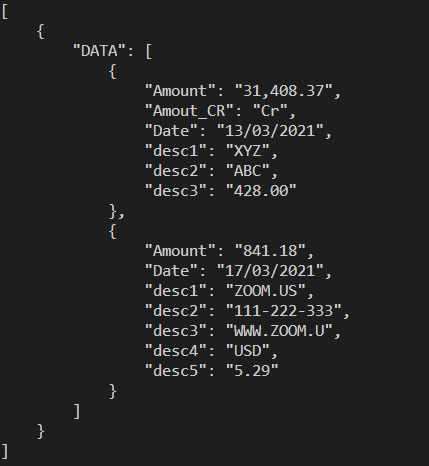
CodePudding user response:
You can use the following code:
import re
res = []
filepath = r'path_to_file'
rx = re.compile(r'^(\d{2}/\d{2}/\d{4})\s (.*?)\s (\d[\d,]*\.\d{2}(?:\s Cr)?)$')
with open(filepath, 'r') as f:
for line in f:
m = rx.search(line.strip())
if m:
res.append(m.groups())
print(res)
The regex is
^(\d{2}/\d{2}/\d{4})\s (.*?)\s (\d[\d,]*\.\d{2}(?: Cr)?)$
Details:
^- start of string(\d{2}/\d{2}/\d{4})- Group 1: date like pattern\s- one or more whitespaces(.*?)- Group 2: any zero or more chars other than line break chars as few as possible\s- one or more whitespaces(\d[\d,]*\.\d{2}(?: Cr)?)- Group 3: a number with 2 digits after decimal separator and an optional sequence of a spaceCr.$- end of string. See the regex demo
CodePudding user response:
Without Cr
Regex would be (\d{2}/\d{2}/\d{4})\s (.*)\s ([.,\d] )\s ([.,\d] )
With Cr
Regex would be (\d{2}/\d{2}/\d{4})\s (.*)\s ([.,\d] )\s ([.,\d] .*)
Tip please don't forget to add g (global flag) to parse whole text in one go.
Sample python code:
import re
regex = r"(\d{2}/\d{2}/\d{4})\s (.*)\s ([.,\d] )\s ([.,\d] .*)"
test_str = ("Date Description Amount\n"
"13/03/2021 XYZ ABC 428.00 31,408.37 Cr\n"
"17/03/2021 ZOOM.US 111-222-333 WWW.ZOOM.U USD 5.29 841.18")
matches = re.finditer(regex, test_str)
for matchNum, match in enumerate(matches, start=1):
print ("Match {matchNum} was found at {start}-{end}: {match}".format(matchNum = matchNum, start = match.start(), end = match.end(), match = match.group()))
for groupNum in range(0, len(match.groups())):
groupNum = groupNum 1
print ("Group {groupNum} found at {start}-{end}: {group}".format(groupNum = groupNum, start = match.start(groupNum), end = match.end(groupNum), group = match.group(groupNum)))